
Data lake : un déploiement progressif et agile
Le data lake est un moyen, non une fin. En effet, il est utilisé pour tester et déployer des cas d’usage* marketing et métier. Il met à profit une infrastructure commune, selon un processus itératif, agile, en commençant petit mais en pensant grand dès le démarrage. La direction marketing peut sponsoriser et bénéficier en premier lieu de ces projets pluridisciplinaires.
Les différentes étapes d’un cas d’usage data lake
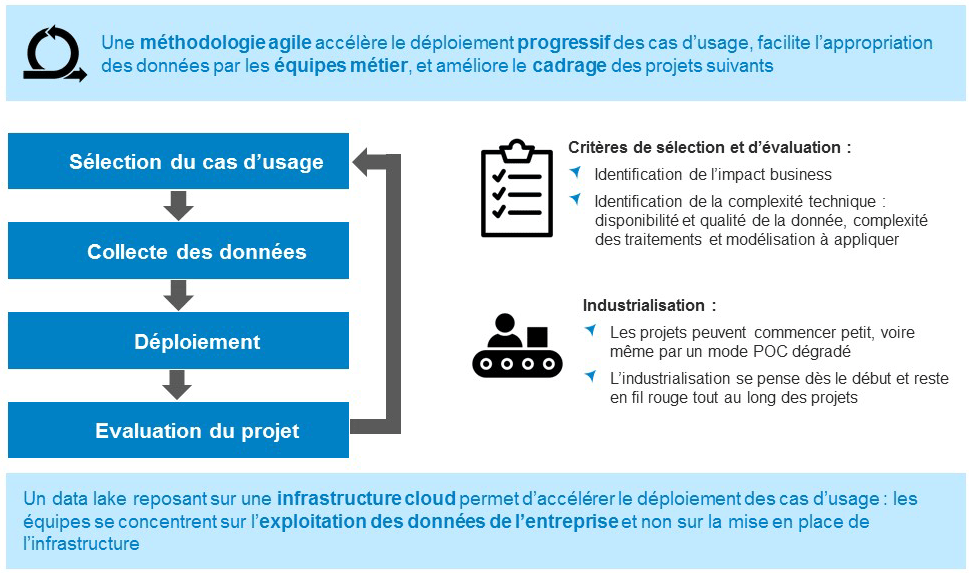
Sélection puis cadrage du cas d’usage : la sélection du cas d’usage s’effectue selon plusieurs critères : les coûts et le ROI espéré du projet, la difficulté de mise en place du projet, notamment par rapport aux équipes et compétences à mobiliser au sein de l’entreprise.
Collecte des données : durant cette phase préparatoire du cas d’usage, les équipes métier et techniques identifient quelles sources de données doivent exploitées par le data lake : s’agit-il de données internes à l’entreprise, de données tierces ou d’open data ? S’agit-il de données structurées (transactions, fichiers clients, …), semi-structurées (données web analytics, données issues d’API, …) ou non structurées (commentaires des clients, emails, …) ? La donnée brute est ensuite chargée dans le data lake, dans un premier temps à la main, et à terme à l’aide d’un flux automatisé. Elle fait ensuite l’objet d’analyses exploratoires et de retraitements éventuels avant utilisation. Cette phase est souvent la plus longue du projet.
Déploiement du cas d’usage : l’équipe technique se charge de la réalisation du cœur du projet, suivant les besoins exprimés par l’équipe métier. En fonction du cas d’usage retenu, l’architecture à mettre en place – constituant simplement une brique du data lake – sera différente :
· S’appuyer sur un data warehouse pour répondre à des besoins de BI / reporting
· Utiliser une machine virtuelle ou un cluster pour réaliser un modèle prédictif, calculer un score ou créer un moteur de recommandation
· Ingérer et traiter des données en temps réel (streaming) à l’aide d’une architecture de pipeline ETL spécifique
Phase d’évaluation : cette dernière phase est parfois négligée mais pourtant importante pour orienter les futurs cas d’usage portés par le data lake. Il s’agit d’évaluer l’impact business du cas d’usage qui vient d’être mis en place : quels ont été les coûts et le ROI effectif du projet ? Il convient de comparer les retombées du cas d’usage par rapport à un processus répondant au même besoin business qui peut être déjà existant au sein de l’entreprise, même si ce dernier est en grande partie manuel (par exemple, réaliser un modèle prédictif n’a de sens que si celui-ci est meilleur que les estimations et projections que les équipes métier ont déjà l’habitude de réaliser régulièrement).
La phase d’évaluation peut également être l’occasion d’organiser un retour d’expérience, soit à destination de l’équipe projet elle-même, soit à destination d’autres entités de l’entreprise. Elle permet de faire le bilan du cas d’usage et d’en relever les pistes d’amélioration à mettre en place dans le cadre d’une nouvelle itération du projet.
Dans ce cadre, Converteo recommande d’intervenir sur une ou plusieurs itérations de cas d’usage, dont la durée moyenne est de 4 à 6 semaines, parfois davantage pour les cas d’usage plus complexes ou nécessitant une préparation plus importante des données. Les coûts humains de setup et de maintenance sont sans comparaison avec des infrastructures datawarehouse legacy.
Commencer petit, mais penser à l’industrialisation dès le démarrage du projet
Le data lake sert de terrain de jeux aux équipes en charge du projet, pouvant ainsi tester leurs cas d’usage en commençant sous la forme d’un POC ou même d’une simple étude. On commencera dans un premier temps par charger des fichiers à la main dans le data lake et travailler sur quelques mois de données, avant de s’attaquer à l’automatisation de flux et au rapatriement de plusieurs années de données.
L’industrialisation s’effectue dans un deuxième temps, mais on la pensera en fil rouge du projet : la mise à l’échelle du projet conditionne, dès le début, la solution technique à mettre en place et à travers elle la réussite du projet.
« Fail fast, succeed faster »
Le data lake est à l’image de la méthodologie agile employée pour les cas d’usage : il se construit au fur et à mesure. Ce n’est pas un outil monolithique, mais un ensemble de différentes briques répondant à un besoin précis.
Le choix d’une infrastructure dans le cloud, soit auprès de public cloud providers (AWS, Microsoft Azure, Google Cloud Platform…), soit auprès de cloud privés, s’avère fondamental : il conditionne le délai de déploiement du cas d’usage et la montée en compétence des équipes marketing et digitales.
Le cloud permet des économies substantielles en coût de mise en place et de maintenance d’infrastructure (la tendance se dirigeant de plus en plus vers le No Ops ou le serverless), les équipes pouvant alors se concentrer rapidement sur le cas d’usage en lui-même, selon la devise du « fail fast, succeed faster. »
On commencera ainsi par mettre en place des cas d’usage simples, mais indispensables pour que les équipes s’approprient les données, les outils à leur disposition, et les premiers retours d’expérience. Au final, l’expérience acquise pourra être mise à profit sur des cas d’usage plus complexes, potentiellement à plus forte valeur ajoutée pour l’entreprise.
* (1) la mécanique marketing et/ou métier, (2) les canaux marketing et/ou services internes concernés et (3) les données nécessaires pour son déploiement et leur mode d’exploitation cible.
Converteo accompagne de nombreux clients dans la mise en place et l’utilisation de data lakes pour répondre à des cas d’usage autour de la connaissance clients et de leur activation online et offline.
Téléchargez notre livre blanc « Comprendre le data lake » en complément de cet article