
Data Lakes CPG : Comment structurer la donnée d’approvisionnement pour l’IA ?
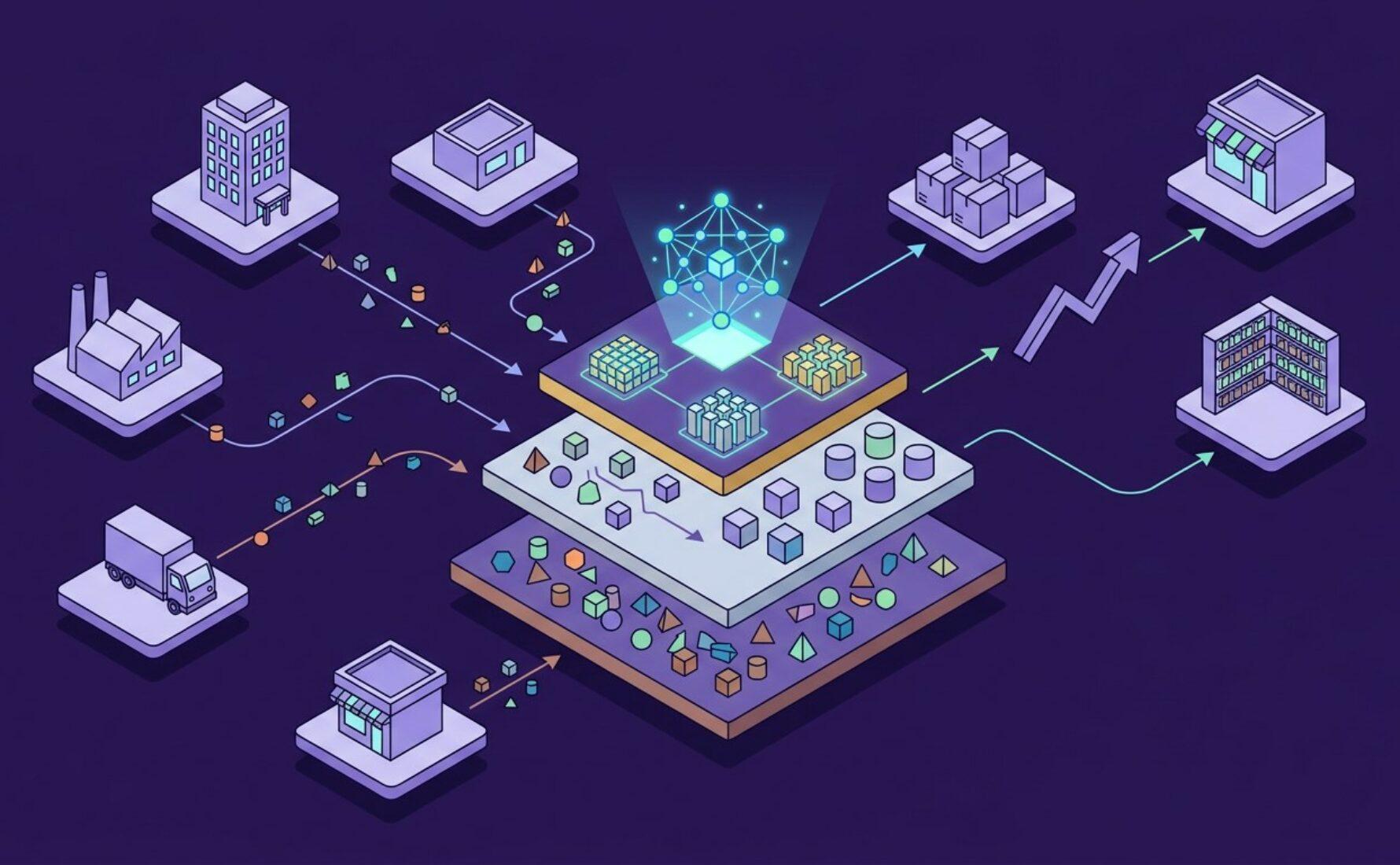
Table des matières
- Les défis de la donnée d’approvisionnement dans le secteur CPG
- Architecture du Data Lake : Du brut au Prêt pour l’IA
- Optimiser la qualité pour maximiser la performance des modèles
L’industrie des produits de grande consommation traverse une mutation profonde où la réactivité face aux fluctuations de la demande ne suffit plus. Pour les acteurs du CPG, l’enjeu est désormais d’anticiper les ruptures et d’optimiser les flux logistiques grâce à l’intelligence artificielle. Pourtant, la majorité des projets échouent non pas à cause des algorithmes, mais en raison d’une base de données fragile et désorganisée.
Le passage d’une gestion réactive à une stratégie prédictive impose de repenser totalement la centralisation des informations. Le Data Lake s’impose alors comme la solution technique idéale pour briser les silos traditionnels entre la production, le transport et les ventes. Sa capacité à stocker des volumes massifs de données brutes offre une flexibilité indispensable pour nourrir des modèles de Machine Learning de plus en plus exigeants.
Structurer efficacement un Data Lake pour le secteur CPG demande toutefois une rigueur méthodologique particulière car les sources sont par nature hétérogènes. Entre les données issues des ERP, les fichiers plats des distributeurs et les relevés logistiques en temps réel, la complexité est maximale et peut parfois exposer l’entreprise à des risques de sécurité si elle est mal encadrée par des outils tiers qui ne garantissent pas la confidentialité. Une architecture mal pensée transforme rapidement le réservoir de données en un marécage inexploitable par les Data Scientists.
Chez Converteo, nous constatons que la réussite d’une stratégie Data IA repose sur une transformation profonde de la donnée d’approvisionnement en actifs actionnables. Cet article détaille les étapes clés pour structurer votre infrastructure de manière à maximiser la précision de vos modèles prédictifs. Il s’agit de passer d’un stockage passif à une plateforme dynamique capable de soutenir la croissance de votre entreprise.
Les défis de la donnée d’approvisionnement dans le secteur CPG
Le secteur de la grande consommation se caractérise par une dispersion historique des données qui rend toute analyse transverse complexe. Les informations d’approvisionnement sont souvent réparties entre plusieurs systèmes qui ne communiquent pas nativement entre eux. L’ERP gère les commandes, le Warehouse Management System s’occupe des stocks physiques, tandis que les outils des prestataires logistiques externes détiennent les preuves de livraison. Cette fragmentation empêche d’avoir une vision de bout en bout de la chaîne de valeur, ce qui pénalise directement la réactivité des décideurs face aux imprévus.
L’un des défis majeurs réside dans la disparité des formats et des fréquences de mise à jour. Tandis que les données internes peuvent être extraites quotidiennement, les données de sell-out provenant des retailers arrivent parfois avec plusieurs jours de retard et sous des nomenclatures différentes. Cette hétérogénéité force les équipes à passer 80% de leur temps sur le nettoyage des données plutôt que sur l’analyse. Il devient donc crucial de travailler sur une standardisation des jeux de données pour pouvoir passer plus de temps sur l’optimisation de la prise de décision.
Enfin, la granularité de la donnée est un enjeu critique trop souvent sous-estimé lors de la conception d’un projet data. Pour prévoir finement la demande, un modèle d’IA a besoin de descendre au niveau de l’article par point de vente et par jour. Or, de nombreuses infrastructures CPG se contentent encore de données agrégées à la semaine ou au niveau régional. Cette perte de précision dans les données d’entrée limite drastiquement la capacité des modèles à identifier les tendances locales ou les signaux faibles, rendant les prévisions de stock moins fiables et augmentant le risque de méventes.
Architecture du Data Lake : Du brut au Prêt pour l’IA
Pour transformer ce chaos informationnel en valeur business, l’adoption d’une architecture dite Medallion au sein du Data Lake est une pratique d’excellence. La couche Bronze reçoit les données brutes telles quelles, permettant une ingestion rapide sans transformation préalable. C’est ici que sont conservés l’historique complet des transactions ERP et les logs de transport. Cette étape garantit la traçabilité totale mais n’est pas encore utilisable pour l’IA car les données sont encore trop polluées par des doublons ou des erreurs de saisie manuelles.
La transition vers la couche Silver représente le cœur du travail de structuration pour le CPG. C’est à ce stade que s’opère l’unification sémantique, où l’on réconcilie par exemple le code article du distributeur avec le code EAN interne. On y applique des règles de gestion strictes pour filtrer les anomalies et normaliser les unités de mesure. C’est dans cette zone que la donnée devient propre et structurée, offrant une base stable pour les analyses descriptives. Pour les modèles d’IA, cette étape est cruciale car elle assure que l’apprentissage se fait sur des données saines et représentatives de la réalité opérationnelle.
La couche Gold est enfin celle qui accueille le Feature Engineering spécifique aux besoins de la Supply Chain. On ne parle plus ici de simples tables de données, mais de variables optimisées pour les algorithmes comme la moyenne mobile des ventes sur 30 jours ou les indices de saisonnalité. Pour un cabinet comme Converteo, cette structuration permet de réduire le temps de mise en production des modèles IA de près de 50%. En préparant ces indicateurs avancés directement dans le Data Lake, on s’assure que tous les modèles utilisent la même définition métier du taux de service ou de la rupture de stock.
Optimiser la qualité pour maximiser la performance des modèles
La performance d’une intelligence artificielle est intrinsèquement liée à la qualité de la gouvernance mise en place autour du Data Lake. Sans un Master Data Management robuste, même l’algorithme le plus sophistiqué produira des résultats erronés, car la base de données ne peut tolérer des informations contradictoires. Il est impératif de définir des propriétaires de données au sein des directions métiers pour valider les référentiels produits, clients et sites logistiques. Cette gouvernance garantit que les changements opérationnels, comme l’ouverture d’un nouvel entrepôt ou le lancement d’une promotion, sont répercutés instantanément dans le flux de données alimentant l’IA.
Les bénéfices d’une donnée d’approvisionnement bien structurée sont tangibles et mesurables très rapidement. Dans nos interventions, nous observons régulièrement que l’intégration de données de trafic routier et de météo en temps réel au sein du Data Lake permet d’affiner les délais de livraison de manière spectaculaire. En croisant ces facteurs externes avec les données de stock historiques, les entreprises CPG parviennent à réduire leurs stocks dormants de 10% à 20% tout en améliorant leur taux de service client. L’IA n’est alors plus une boîte noire, mais un outil d’aide à la décision qui s’appuie sur une réalité terrain documentée.
La lutte contre les ruptures de stock en rayon constitue l’application la plus rentable de cette structuration. En croisant les données de transport avec les stocks en magasin, l’IA peut détecter des anomalies de livraison avant même qu’elles n’impactent le consommateur final. Cette proactivité n’est possible que si le Data Lake est capable d’absorber et de traiter les données à haute fréquence. En conclusion, structurer sa donnée d’approvisionnement n’est pas un projet purement technique, mais une fondation stratégique. Les entreprises qui investissent aujourd’hui dans cette architecture seront celles qui domineront le marché demain grâce à une agilité hors pair.








