
Architecture agent vocal : pipeline vs voice-to-voice



Partner Data / IA et Expert Agentique chez Converteo, David Guede est spécialisé dans le déploiement d’architectures d’IA en production. En collaboration étroite avec lui, Samuel Nespolo-Besson, Senior Manager chez Converteo, co-pilote l’offre de transformation des services clients via l’IA agentique et accompagne les entreprises dans l’intégration de solutions conversationnelles intelligentes (voicebots, chatbots) pour optimiser durablement leurs parcours utilisateurs.
À retenir
- Il existe aujourd’hui deux grandes architectures pour bâtir un agent vocal : la chaîne pipeline (Speech-to-Text, puis LLM, puis Text-to-Speech) et le modèle voice-to-voice, qui traite la parole de bout en bout.
- Le voice-to-voice gagne sur la latence (de l’ordre d’une seconde, contre près de trois pour un pipeline) et préserve le naturel de la voix : émotions, respirations, hésitations.
- Le pipeline garde de vrais atouts : modularité, contrôle fin à chaque étape, et capacité à capitaliser sur des briques LLM matures déjà déployées par l’entreprise.
Quand on parle d’« agent vocal », on parle en réalité de deux familles d’architectures bien distinctes. La distinction n’a rien d’un détail technique : elle conditionne la latence ressentie par l’utilisateur, le naturel de l’échange, le coût d’exploitation et la complexité du système à maintenir.
L’architecture pipeline : STT, LLM, TTS
C’est l’architecture historique, modulaire, éprouvée. Elle décompose la conversation en trois grandes étapes successives.
Étape 1, le Speech-to-Text (STT) L’utilisateur parle, et sa voix est transcrite en texte. C’est la brique « écoute ». Les modèles actuels atteignent un taux d’erreur sur les mots compris entre 4 et 6 %, soit à peu près le niveau d’un traducteur professionnel.
Étape 2, le LLM Le texte est passé à un modèle de langage qui devient le cerveau du système. C’est lui qui raisonne, qui décide, qui appelle des outils pour aller chercher une information (via un RAG, par exemple), qui interagit avec les systèmes métier pour écrire ou modifier des données, et qui est encadré par des garde-fous pour éviter hallucinations et dérapages. Le LLM produit une réponse, écrite.
Étape 3, le Text-to-Speech (TTS) Cette réponse écrite est lue à voix haute par un module de synthèse vocale. C’est la brique « parole ». Les voix synthétiques modernes sont devenues quasi indiscernables d’une voix humaine.

L’avantage de cette architecture, c’est sa modularité. Chaque brique peut être choisie indépendamment, mise à jour, remplacée. On peut piloter finement les coûts en choisissant un LLM plus ou moins puissant au centre du dispositif. On peut imposer des contrôles précis entre les étapes. C’est aussi l’architecture la plus naturelle quand on souhaite réutiliser des composants déjà déployés ailleurs dans l’entreprise.
Son inconvénient, c’est le passage obligé par l’écrit. Or l’écrit aplatit la conversation. Toute l’information para-verbale, le ton, l’émotion, l’hésitation, le rythme, disparaît à l’étape de la transcription. Le temps cumulé des trois étapes pèse également sur la latence : un pipeline classique introduit facilement près de 3 secondes entre la fin d’une phrase et le début de la réponse.
L’architecture voice-to-voice : un seul modèle qui écoute et qui parle
Le voice-to-voice change radicalement de paradigme. Plus de pipeline, plus de transcription intermédiaire : un seul modèle prend en entrée la voix de l’utilisateur, raisonne, décide, appelle ses outils, puis produit directement une voix en sortie.
L’utilisateur parle. Le modèle l’entend, comprend, traite, et répond à la volée. Le texte n’apparaît jamais dans le circuit principal.
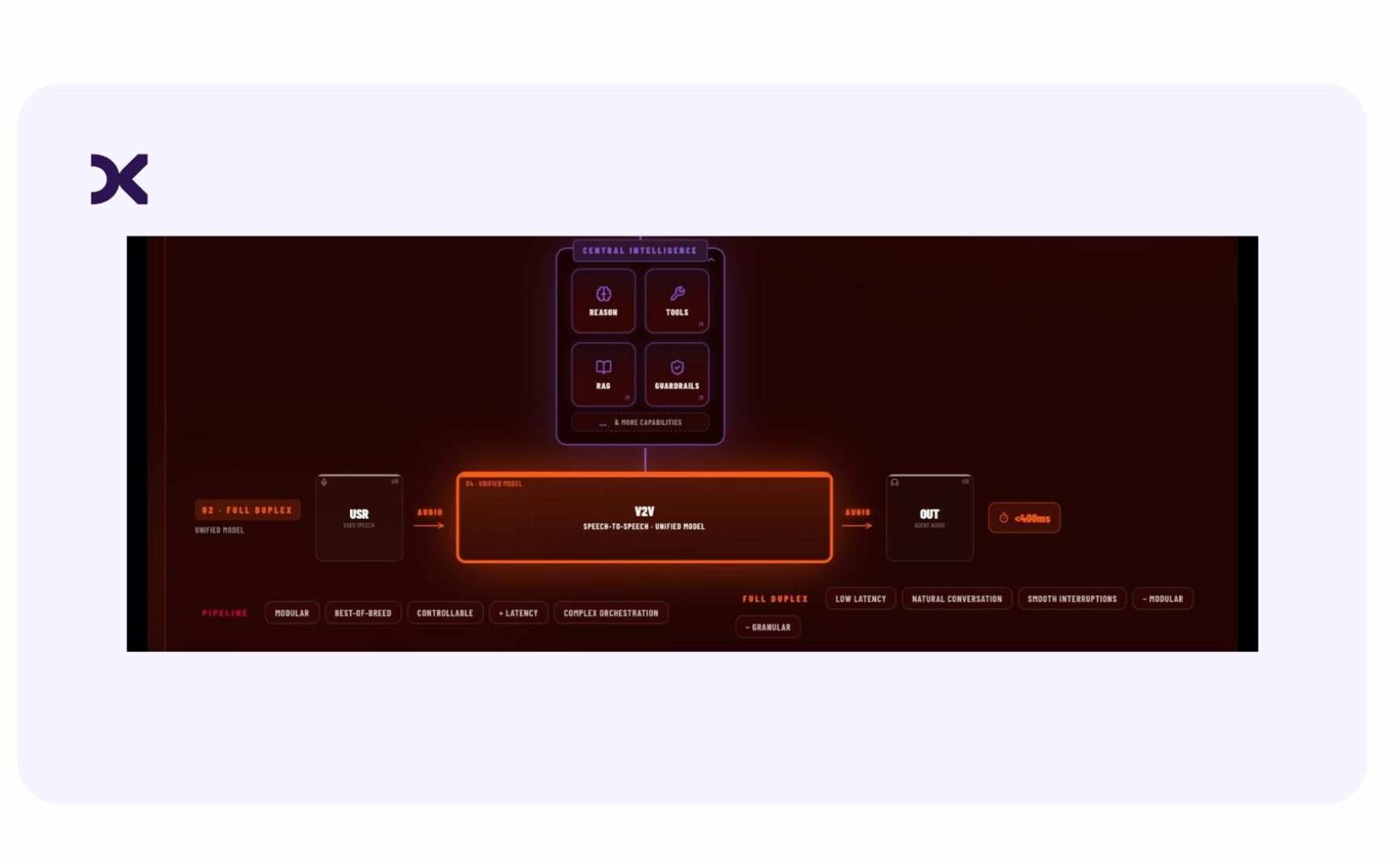
Cette simplification a deux conséquences fortes.
La première, c’est la latence. En se passant de la transcription et de la synthèse séparées, on descend autour d’une seconde, voire moins. Ce n’est pas un détail : c’est la différence entre une conversation fluide et un échange poussif où chaque tour de parole se fait attendre.
La seconde, c’est la richesse du signal vocal. Comme la voix n’est jamais convertie en texte, le modèle perçoit ce qu’un système de transcription ne peut pas capter par construction : le stress, l’agacement, l’hésitation. Symétriquement, en sortie, il peut glisser des respirations, des micro-hésitations, parfois même des bruits de clavier qui rendent l’échange troublant de naturel.
C’est précisément pour ces deux raisons qu’Orange a fait ce choix en mettant en production son agent vocal Sharlie, sur la marque Sosh : une expérience proche d’un échange humain, sans cette attente caractéristique qui trahit immédiatement un bot.
Pipeline ou voice-to-voice : comment choisir
Il n’y a pas de bonne réponse universelle. Le choix dépend de plusieurs paramètres.
- Le naturel attendu de l’interaction. Pour une expérience conversationnelle proche d’un échange humain, où l’on veut percevoir les émotions et répondre du tac au tac, le voice-to-voice est aujourd’hui imbattable. Pour des cas d’usage plus transactionnels (consulter un solde, déclencher une commande simple), un pipeline bien réglé fait très bien le travail.
- La tolérance à la latence. Dès qu’on dépasse une à deux secondes de blanc, l’utilisateur perçoit qu’il parle à une machine. Sur des cas d’usage où la fluidité prime (sinistre en urgence, assistance dans la voiture), le voice-to-voice s’impose.
Le besoin de contrôle et d’auditabilité. L’architecture pipeline a un avantage qui n’est pas anodin : entre chaque étape, on peut inspecter ce qui circule, journaliser, filtrer. Sur des sujets réglementaires sensibles (finance, santé, conformité), cette traçabilité fine peut faire pencher la balance.
- La maturité de l’écosystème déjà déployé. Beaucoup d’entreprises ont déjà des briques LLM en production, des bases de connaissance branchées, des garde-fous éprouvés. Le pipeline permet de capitaliser dessus sans tout reconstruire. Le voice-to-voice, lui, implique souvent de repartir de modèles plus récents et moins matures côté outillage métier.
- Le coût. À ce jour, le voice-to-voice « full duplex » reste la brique la plus chère. Un pipeline avec un LLM intermédiaire bien dimensionné peut se révéler significativement plus économique, surtout à l’échelle.
Pipeline et voice-to-voice ne sont pas deux générations qui se succèdent : ce sont deux options qui coexistent, chacune avec sa propre logique. Le voice-to-voice ouvre des expériences inédites en matière de fluidité et de naturel. Le pipeline reste l’architecture de référence pour beaucoup de cas d’usage où la modularité, le contrôle et la maîtrise des coûts priment.
Le vrai sujet, dans les deux cas, n’est plus la voix elle-même. Il se joue au milieu : dans la capacité du système à raisonner, à appeler les bons outils, à passer la main à un humain au bon moment, et à tenir dans le temps. .








