
Agents vocaux en 2026 : qu’est-ce qui change vraiment ?



Partner Data / IA et Expert Agentique chez Converteo, David Guede est spécialisé dans le déploiement d’architectures d’IA en production. En collaboration étroite avec lui, Samuel Nespolo-Besson, Senior Manager chez Converteo, co-pilote l’offre de transformation des services clients via l’IA agentique et accompagne les entreprises dans l’intégration de solutions conversationnelles intelligentes (voicebots, chatbots) pour optimiser durablement leurs parcours utilisateurs.
À retenir
- La voix n’a pas attendu 2026 pour être bonne. Dès 2018, Google Duplex réservait un rendez-vous au téléphone avec des hésitations et des onomatopées bluffantes. Ce qui manquait n’était pas la qualité vocale, mais l’intelligence derrière.
- Ce qui a changé, c’est le milieu, pas les extrémités. Le vrai saut, c’est la capacité des modèles à raisonner, décider, appeler des outils et s’orchestrer entre eux. C’est ce « cerveau » qui rend enfin la voix utile.
- Les briques techniques sont mûres, mais le diable est dans les détails. Reconnaissance, synthèse et détection d’émotion ont atteint un niveau quasi humain ; les vrais défis aujourd’hui se jouent sur l’interruption, la latence et le bruit ambiant.
En 2018, une démonstration a stupéfié l’industrie. Sur scène, un assistant Google appelait un salon de coiffure pour réserver un rendez-vous au nom de sa propriétaire. Il hésitait, ponctuait ses phrases de « euh » et de « mm-mm », négociait un créneau. Au bureau, on s’arrêtait pour écouter : on tenait là, croyait-on, le moment de bascule. Les assistants vocaux allaient passer nos coups de fil à notre place.
Puis il ne s’est (presque) rien passé.
Pendant des années, cette promesse est restée une démo. La voix synthétique était déjà excellente, et pourtant, personne n’en parlait vraiment. Il aura fallu attendre 2026 pour que le sujet explose, que les valorisations des spécialistes de la voix s’envolent et que les premiers agents vocaux passent réellement en production. La question s’impose donc d’elle-même : si la voix était déjà là en 2018, qu’est-ce qui a vraiment changé ?
Ce n’est pas que la voix qui a progressé, c’est le milieu
La réponse tient en une phrase entendue tout au long de notre événement : depuis 2018, les extrémités de la chaîne (comprendre la parole, la synthétiser) n’ont pas connu de révolution. Ce qui a changé, c’est tout ce qu’il y a au milieu.
Au milieu, c’est la capacité du système à raisonner, à prendre des décisions, à aller chercher la bonne information, à appeler des outils pour agir, et à passer la main au bon moment. C’est ce « cerveau » qui transforme une jolie voix en un interlocuteur réellement utile. Et c’est précisément cette couche-là qui a fait un bond ces derniers mois.
Pour bien comprendre, il faut distinguer deux architectures.
L’architecture pipeline (STT → LLM → TTS)
L’utilisateur parle, sa voix est transcrite en texte (Speech-to-Text), ce texte est transmis à un modèle de langage (LLM) capable de raisonner, d’appeler des outils, de chercher de l’information dans une base de connaissances et d’être encadré par des garde-fous, puis la réponse écrite est lue à voix haute par un module de synthèse (Text-to-Speech). C’est l’architecture historique, modulaire et éprouvée.
L’architecture duplex (voice-to-voice)
L’utilisateur parle, et un seul modèle prend directement l’entrée vocale. Ce modèle raisonne, décide, appelle ses outils et répond à la volée, sans jamais passer par une transcription écrite. L’architecture devient radicalement plus simple, et l’expérience beaucoup plus naturelle.
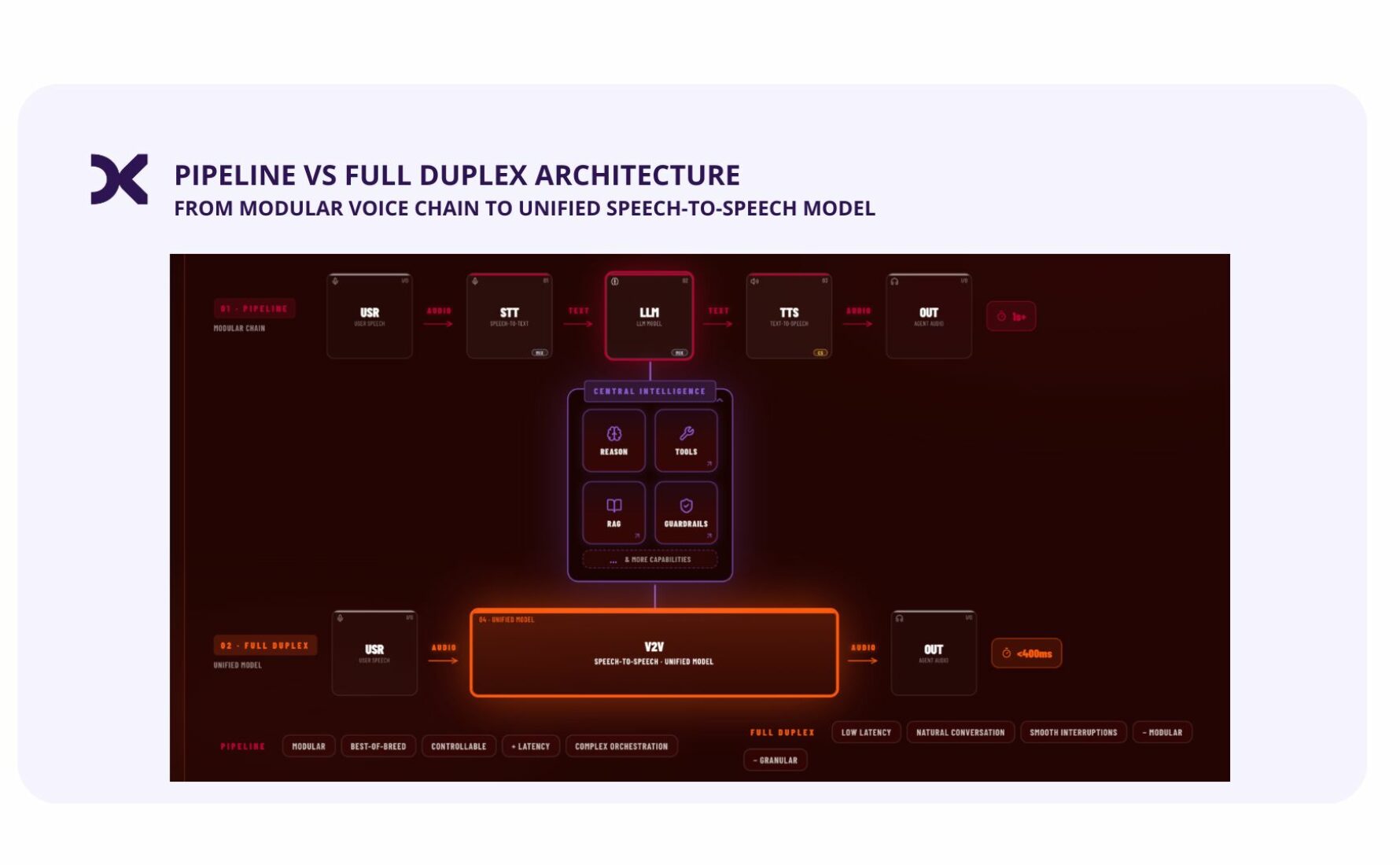
La différence n’est pas qu’esthétique. Dans une chaîne STT/TTS, le passage par le texte coûte du temps et fait perdre une partie de la richesse de la voix (les émotions, le rythme, les nuances). Le voice-to-voice, lui, traite le son directement.
IA vocale : l’état de l’art
Si le « milieu » a tout changé, c’est aussi parce que les briques de base ont atteint un niveau de maturité impressionnant. Décomposons ce que sait faire la technologie aujourd’hui, des deux côtés de la conversation.
L’agent vocal sait-il écouter ?
Les modèles de reconnaissance vocale affichent désormais un taux d’erreur sur les mots compris entre 4 et 6 %. Pour donner un ordre de grandeur, c’est à peu près le niveau d’un traducteur professionnel. La transcription n’est plus le maillon faible.
Deuxième avancée majeure : on sort enfin de l’anglais. Pendant longtemps, l’essentiel des démonstrations se faisait dans la langue de Shakespeare. Les modèles couvrent aujourd’hui les langues européennes avec un niveau de qualité bien plus exploitable pour nos marchés.
Enfin, les modèles voice-to-voice savent faire quelque chose dont un système de transcription est incapable par construction : détecter les émotions. Un modèle qui traite la voix directement perçoit le stress, l’agacement ou l’hésitation – des informations qui disparaissent dès qu’on passe par du texte.
L’agent vocal sait-il parler ?
Côté synthèse, les voix sont devenues quasi indiscernables d’une voix humaine. Au point que cela soulève de vraies questions, et pas des moindres. Les modèles savent désormais reproduire les hésitations, les chuchotements, et même glisser des respirations ou des bruits de clavier qui rendent l’échange troublant de naturel.
C’est aussi pour cela que le voice-to-voice marque un tournant : là où un pipeline STT/TTS « aplatit » la conversation en la faisant transiter par l’écrit, le traitement direct du son préserve l’émotion et le naturel d’un bout à l’autre.
Quels défis et limites pour l’IA vocale ?
La technologie est mûre, mais elle n’est pas magique. Les combats d’aujourd’hui ne se jouent plus sur la qualité de la voix, ils se jouent sur la fluidité de l’échange. Voici les notions clés à connaître.
VAD (Voice Activity Detection)
Littéralement, la détection d’activité vocale : à quel moment le système doit considérer que l’utilisateur parle et l’écouter. En apparence trivial. Sauf que dans le métro, il faut distinguer votre voix de celle du voisin assis à côté. Et que se passe-t-il quand on appelle un agent vocal avec la télévision allumée derrière soi ? La VAD, c’est tout l’art de « débruiter » : isoler la voix de la bonne personne pour ne transmettre qu’elle au modèle.
Les mots très courts
Un « oui » ou un « voilà » sont si brefs qu’il faut au système une vraie finesse pour reconnaître qu’il s’agit bien d’une prise de parole, et non d’une simple perturbation sonore. Un défi sous-estimé.
Le barge-in (l’interruption)
C’est sans doute la fonction la moins spectaculaire, et pourtant l’une des plus déterminantes. Pendant longtemps, on ne pouvait pas couper un bot : il fallait le laisser dérouler son message jusqu’au bout. Toute personne ayant déjà reçu un appel commercial le sait — ne pas pouvoir interrompre un bot, c’est l’enfer. À l’inverse, un bot qui se coupe parce qu’on passe dans un endroit bruyant est tout aussi pénible. Savoir interrompre et être interrompu au bon moment est devenu un marqueur de qualité.
La latence
Le temps entre la fin de votre phrase et le début de la réponse. C’est ici que l’architecture compte le plus : une chaîne STT/TTS introduit facilement près de 3 secondes d’attente, là où le voice-to-voice descend autour d’une seconde, voire moins. La différence entre une conversation et un échange poussif.
L’orchestration
Le dernier maillon, et peut-être le plus stratégique. Un agent vocal performant n’est presque jamais un modèle unique, mais un ensemble d’agents spécialisés qui se passent la main selon les situations — et qui savent escalader vers un humain quand c’est nécessaire. La règle qui résume tout : mieux vaut un agent doté d’un modèle moyen mais bien orchestré qu’un agent équipé du meilleur modèle du monde mais mal orchestré.
Reste alors la vraie question, celle que se posent désormais les marques : comment construire un agent vocal qui tienne dans le temps, qui ne déraille pas, qui reste fluide, et rentable ? C’est tout l’enjeu de la mise en production.






