
Data Catalog industriel : Cartographier ses données avant de lancer son premier cas d’usage IA
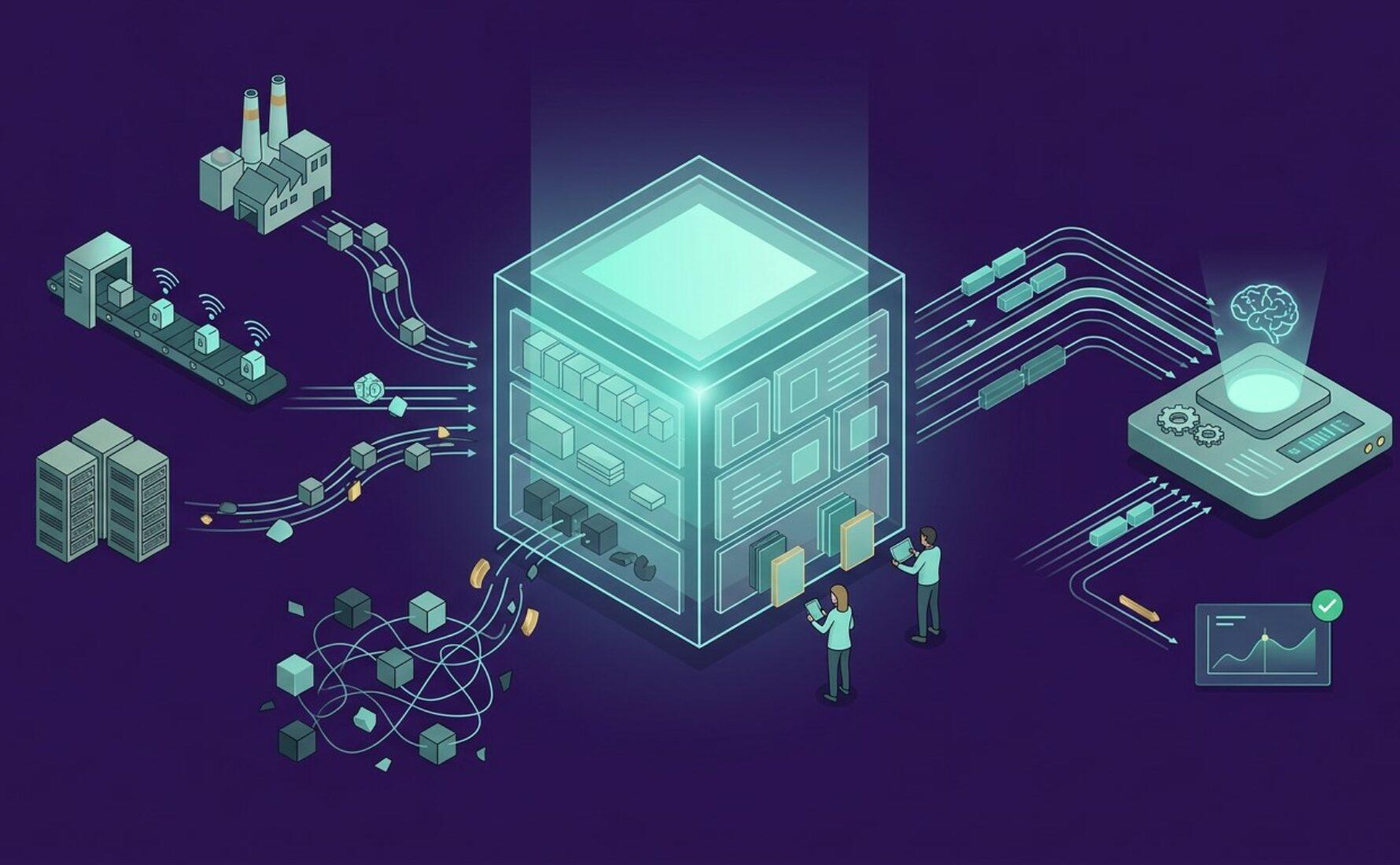
Table des matières
- L’illusion du raccourci : pourquoi l’IA échoue sans cartographie préalable
- Le Data Catalog comme socle de la confiance et de la qualité
- Méthodologie pour une cartographie orientée IA-Ready
- Passer de la théorie à l’action : choisir les bons outils et process
L’essor fulgurant de l’intelligence artificielle au sein du secteur industriel promet des gains d’efficacité sans précédent, transformant les chaînes de production en écosystèmes intelligents. Pourtant, derrière les promesses de maintenance prédictive ou d’optimisation énergétique, une réalité plus sombre freine de nombreux projets : la méconnaissance profonde du patrimoine informationnel. Sans une vision claire des actifs disponibles, les entreprises se lancent dans une course à l’innovation sur des sables mouvants.
La précipitation vers le premier cas d’usage IA occulte souvent une étape fondamentale que le cabinet Converteo juge pourtant indispensable : la mise en place d’un Data Catalog industriel. Ce dispositif ne doit pas être perçu comme un simple inventaire technique, mais comme la fondation stratégique de toute ambition technologique sérieuse. Cartographier ses données avant d’entraîner le moindre algorithme est le seul moyen de garantir la pertinence des résultats futurs.
De nombreux chefs de projet sous-estiment l’hétérogénéité des sources au sein d’une usine ou d’une infrastructure logistique complexe. Entre les capteurs IoT, les systèmes ERP vieillissants et les bases de données locales, le volume de Dark Data — ces données collectées mais inexploitées ou non documentées — explose littéralement. Le Data Catalog intervient alors pour structurer ce chaos et transformer des flux bruts en actifs intelligibles et actionnables par les équipes spécialisées.
Dans cette introduction à la maturité data, nous explorerons pourquoi la cartographie sémantique est le rempart indispensable contre l’échec des projets d’intelligence artificielle. Nous verrons comment le Data Catalog permet de passer d’une approche artisanale à une échelle industrielle, assurant ainsi la pérennité de vos investissements technologiques. L’objectif est simple : faire de la donnée un langage commun entre les experts métiers et les ingénieurs de la donnée.
L’illusion du raccourci : pourquoi l’IA échoue sans cartographie préalable
Vouloir déployer une intelligence artificielle sans une connaissance exhaustive de ses données revient à construire un édifice sans plan de fondations. Dans l’industrie, ce raccourci est particulièrement dangereux car les décisions automatisées impactent directement la sécurité des biens et des personnes. Le coût caché de la donnée non qualifiée est immense. Des études sectorielles montrent que les data scientists consacrent encore aujourd’hui près de 80% de leur temps de travail à la recherche, au nettoyage et à la compréhension des données plutôt qu’à la modélisation proprement dite. Cette inefficacité opérationnelle pèse lourdement sur le retour sur investissement des initiatives IA et décourage souvent les directions générales après quelques mois de tests infructueux.
Le risque majeur de l’absence de cartographie réside dans les biais d’analyse et les erreurs d’inférence. Si un algorithme de détection d’anomalies est alimenté par des datasets dont on ignore la provenance exacte ou la fréquence de mise à jour, les résultats seront au mieux inutilisables, au pire trompeurs. Sans un dictionnaire précis des métadonnées, il est impossible de savoir si une chute de pression enregistrée par un capteur est une défaillance réelle ou une simple erreur de calibration de l’instrument. La cartographie permet de lever ces zones d’ombre en documentant le contexte de collecte, garantissant ainsi que l’IA travaille sur une matière première fiable et représentative de la réalité du terrain industriel.
Le Data Catalog comme socle de la confiance et de la qualité
Pour transformer l’essai du premier cas d’usage, le Data Catalog industriel doit être envisagé comme un outil de gouvernance et de confiance. Contrairement à une simple base de données, le catalogue offre une visibilité sur le lignage des données, aussi appelé Data Lineage. Cette fonctionnalité est cruciale pour l’explicabilité de l’IA, une exigence croissante des régulateurs et des directions métiers. Savoir exactement d’où vient une information, quelles transformations elle a subies et qui en est le propriétaire permet de valider chaque étape de la chaîne de valeur algorithmique. Dans un scénario de maintenance prédictive, le catalogue permet d’identifier instantanément tous les flux corrélés à une panne spécifique, facilitant ainsi l’apprentissage supervisé.
La qualité des données est le second pilier que le catalogue vient consolider. En centralisant les indicateurs de santé des datasets, le Data Catalog permet aux équipes de définir des standards de complétude et de précision indispensables à l’IA. Un catalogue bien renseigné indique non seulement où se trouve la donnée, mais aussi son niveau de fraîcheur et sa fiabilité historique. Pour un industriel, c’est la différence entre une IA qui prédit une panne avec 95% de certitude et une boîte noire dont personne n’ose suivre les recommandations par peur d’un arrêt de production injustifié. La confiance est le moteur de l’adoption, et cette confiance se construit dès la phase de catalogage.
Méthodologie pour une cartographie orientée IA-Ready
Initier une démarche de cartographie demande une méthode rigoureuse qui priorise les actifs critiques. Il ne s’agit pas de tout recenser de manière exhaustive dès le premier jour, mais de se concentrer sur les sources de données qui alimenteront le premier cas d’usage IA identifié. Cela commence par l’identification des données structurées issues des automates programmables et des ERP, mais aussi des données non structurées comme les rapports de maintenance ou les images thermiques. Cette étape nécessite une collaboration étroite entre les informaticiens et les experts métiers qui détiennent la connaissance sémantique. Ce sont ces derniers qui peuvent expliquer qu’une valeur de température aberrante correspond en réalité à une phase de nettoyage normale de la machine.
L’implication des « Subject Matter Experts » dans la définition sémantique du catalogue est le facteur clé de succès. Le Data Catalog doit traduire les termes techniques en concepts métiers compréhensibles par tous. Par exemple, une adresse hexadécimale de capteur dans un système de contrôle-commande doit être associée au concept de « Débit de sortie ligne 4 » dans le catalogue. Cette couche de compréhension mutuelle permet d’accélérer drastiquement la phase de préparation des données pour les futurs projets. En créant ce pont sémantique, l’entreprise s’assure que ses futurs modèles d’IA ne seront pas de simples exercices mathématiques, mais des outils véritablement connectés aux enjeux de production et aux réalités opérationnelles.
Passer de la théorie à l’action : choisir les bons outils et process
Le choix de la solution technologique pour porter ce Data Catalog industriel est une décision structurante. Le marché propose aujourd’hui des outils de Data Catalog modernes capables d’automatiser une grande partie de la découverte des métadonnées grâce au « machine learning » interne à la plateforme. Ces outils de nouvelle génération s’intègrent nativement dans les architectures data cloud ou hybrides, permettant une mise à jour en temps réel de la cartographie. Il est essentiel de privilégier des solutions qui favorisent la collaboration, où chaque utilisateur peut noter la qualité d’un dataset ou suggérer une définition. Le catalogue devient alors un espace vivant, évoluant au rythme des transformations de l’outil de production et des nouveaux besoins analytiques.
Au-delà de l’outil, c’est l’intégration du catalogue dans les processus de développement qui fera la différence. Chaque nouveau projet d’IA devrait désormais commencer par une consultation du Data Catalog pour vérifier la disponibilité des ressources nécessaires. Si les données manquent ou sont de mauvaise qualité, le projet doit intégrer une phase de remédiation dès sa conception. Cette discipline organisationnelle transforme le catalogue d’une contrainte administrative en un accélérateur de projets. En fin de compte, investir dans un Data Catalog industriel est le meilleur moyen de sécuriser le passage à l’échelle de l’intelligence artificielle, transformant un premier succès expérimental en une véritable stratégie de compétitivité durable.
En conclusion, la cartographie des données n’est pas une option facultative mais le passage obligé pour toute industrie souhaitant tirer profit de l’IA. En structurant votre patrimoine data, vous réduisez les délais de mise en œuvre, fiabilisez vos modèles et engagez vos collaborateurs autour d’une vision partagée de l’information. Cette fondation solide est l’assurance que votre premier cas d’usage ne sera que le début d’une transformation profonde et réussie. Pour réussir votre trajectoire data, les experts Converteo vous accompagnent dans la définition d’une stratégie claire et orientée résultats.










