
Data Pipelines industriels : Nourrir l’IA Agentique pour décupler la productivité Supply
Les chaînes d’approvisionnement mondiales traversent une zone de turbulences inédite, où pénuries soudaines, instabilité géopolitique et inflation des coûts imposent une réactivité que les processus manuels ne peuvent plus du tout soutenir. Face à cette complexité grandissante, les grandes entreprises cherchent désespérément de nouveaux leviers d’optimisation structurelle pour maintenir leurs marges et garantir la continuité de leurs opérations commerciales.
C’est très exactement dans ce contexte de tension que l’IA agentique émerge comme le relais de croissance incontournable, dépassant très largement les limites de l’automatisation classique. Contrairement aux algorithmes traditionnels qui se contentent de recommander des actions, ces agents autonomes perçoivent leur environnement, raisonnent et exécutent des tâches complexes de bout en bout. D’ici peu, une grande part des applications d’entreprise intégreront cette forme d’intelligence artificielle agentique pour transformer radicalement la gestion des opérations logistiques.
Toutefois, cette promesse séduisante d’une chaîne intelligente et résiliente se heurte à une réalité technique majeure et souvent sous-estimée. L’intelligence artificielle agentique, aussi sophistiquée soit-elle, n’est absolument rien sans une donnée de qualité, acheminée de manière fiable et continue. Un agent autonome privé d’un flux d’informations précis et actualisé prendra inévitablement des décisions erronées, amplifiant les dysfonctionnements au lieu de les résoudre efficacement.
C’est ici que réside notre thèse centrale : la nécessité vitale des data pipelines industriels pour transformer la donnée brute en productivité Supply. Construire cette infrastructure robuste et évolutive n’est plus une simple question d’ingénierie informatique de bas niveau, mais un impératif stratégique absolu pour nourrir ces nouveaux cerveaux artificiels et décupler concrètement l’efficacité opérationnelle de l’ensemble de votre chaîne de valeur.
L’IA Agentique : Le nouveau cerveau autonome de la Supply Chain
De l’analytique prédictive à l’action autonome
L’évolution technologique récente marque une rupture fondamentale dans la gestion quotidienne des flux logistiques. Historiquement, l’analytique prédictive permettait d’anticiper les ruptures en fournissant des tableaux de bord sophistiqués aux planificateurs, qui devaient ensuite interpréter les signaux et ajuster manuellement les paramètres dans les différents systèmes. Aujourd’hui, l’intelligence artificielle agentique franchit un cap décisif en éliminant cette intervention humaine systématique. Les agents autonomes ne se limitent plus à alerter sur une situation critique, ils prennent en charge la résolution du problème de manière totalement proactive. Dotés d’un raisonnement algorithmique particulièrement avancé, ils analysent une multitude de scénarios en temps réel, évaluent les coûts associés, négocient directement avec les systèmes des fournisseurs et valident des commandes de réapprovisionnement sans aucune supervision humaine constante. Cette transition majeure vers l’action autonome libère un temps précieux pour les équipes opérationnelles, qui peuvent enfin se concentrer sur la vision stratégique globale et la gestion des exceptions les plus complexes du marché.
Cas d’usage concrets en logistique
La théorie fascinante de l’intelligence artificielle agentique se matérialise déjà à travers des applications très concrètes qui redéfinissent les standards de la supply chain. Imaginons un instant un agent autonome affecté au pilotage du réapprovisionnement dynamique au sein d’un vaste réseau de distribution international. Si une perturbation météorologique retarde un navire transportant des composants critiques, l’agent détecte l’anomalie instantanément grâce aux flux d’informations externes. Sans attendre la moindre validation hiérarchique, il identifie les usines impactées, recherche des fournisseurs alternatifs locaux, simule les surcoûts logistiques et passe les commandes nécessaires pour éviter un arrêt catastrophique de la production. Un autre exemple particulièrement probant concerne la réallocation de stock en cours de route. Lors d’un pic de demande soudain dans une région spécifique suite à une tendance virale inattendue, un agent dédié à l’optimisation des flux peut intercepter virtuellement les camions de livraison en transit et rediriger la marchandise vers les entrepôts sous tension, maximisant ainsi les opportunités de ventes tout en minimisant drastiquement les coûts de stockage inutiles sur les autres zones géographiques.
Pourquoi le Data Pipeline industriel est le prérequis absolu
Le syndrome du « Garbage In, Garbage Out » à l’échelle des agents
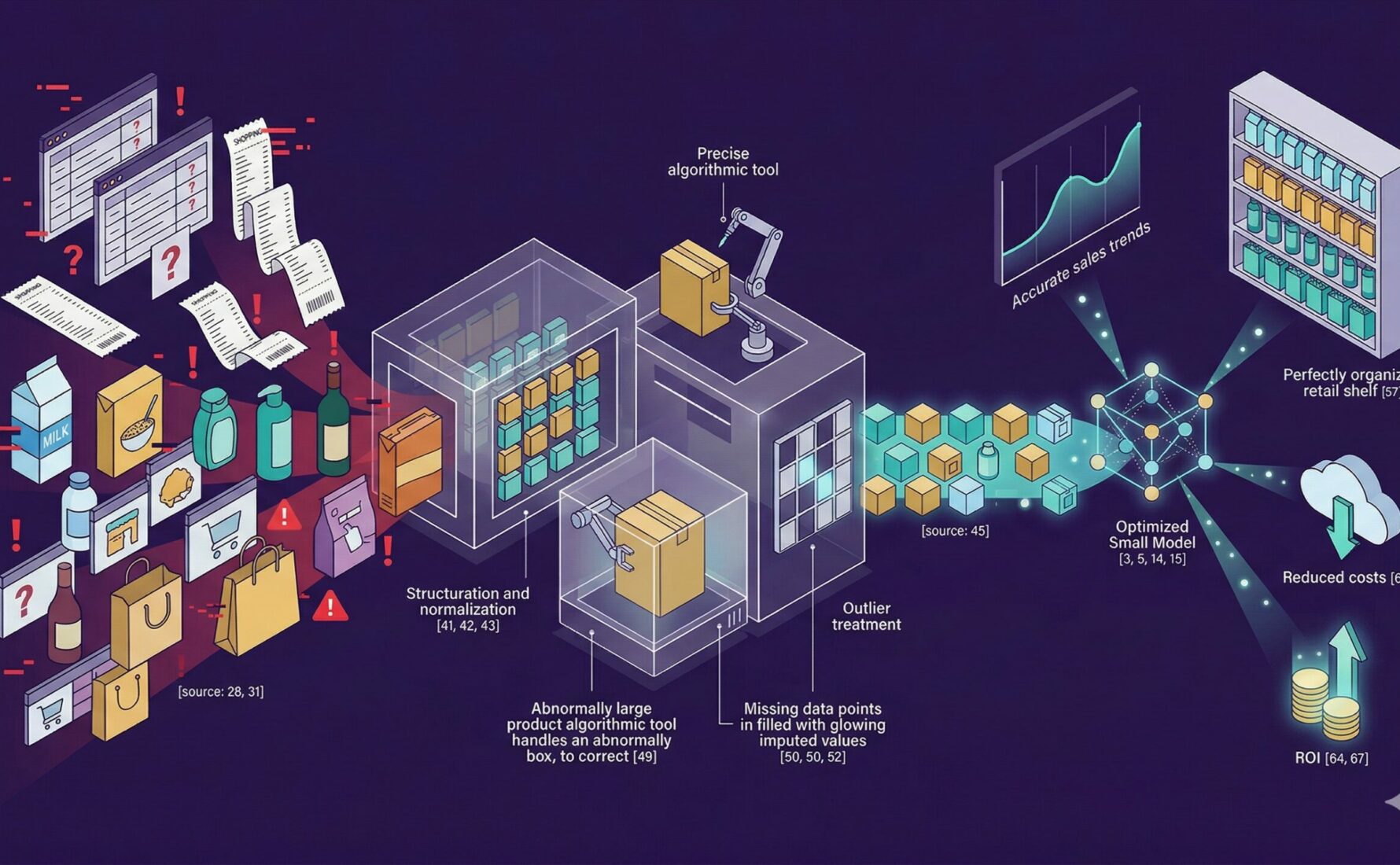
Le potentiel transformateur immense des agents autonomes est indéniable, mais il expose également les grandes organisations à des risques financiers totalement inédits si les fondations techniques sont négligées. Le célèbre adage informatique « Garbage In, Garbage Out », signifiant que des données d’entrée erronées produisent inévitablement des résultats absurdes, prend une dimension dramatique avec l’intelligence artificielle agentique. Lorsqu’un algorithme classique se trompe, il génère simplement un rapport inexact qu’un humain vigilant peut corriger. En revanche, lorsqu’un agent autonome base son raisonnement sur des informations fausses, obsolètes ou incomplètes, il prend immédiatement des décisions coûteuses de manière totalement automatisée. Une simple erreur de conversion d’unité dans une base de données mal entretenue peut conduire un agent zélé à commander dix mille palettes complètes au lieu de dix mille unités individuelles, saturant instantanément la capacité physique de l’entrepôt et paralysant le fonds de roulement de l’entreprise. C’est la raison pour laquelle la qualité des données supply chain n’est plus un sujet secondaire, mais le socle absolu de la confiance que les comités de direction peuvent accorder à ces puissants systèmes.
Caractéristiques d’un pipeline taillé pour l’Agentic AI
Pour s’affranchir de ces catastrophes opérationnelles potentielles et garantir des performances industrielles optimales, l’architecture d’intégration des données doit impérativement adopter des standards de qualité extrêmement rigoureux. Les anciennes approches basées sur des extractions de données sporadiques fonctionnant par lots isolés en fin de journée sont aujourd’hui totalement inadaptées aux exigences de réactivité fulgurante de l’Agentic AI. Un data pipeline industriel moderne doit être pensé dès sa conception pour traiter les informations en temps réel ou quasi-temps réel, assurant une fraîcheur de la donnée absolument irréprochable. Il doit également se distinguer par une robustesse à toute épreuve, en intégrant des mécanismes d’observabilité très poussés pour alerter les équipes de data engineering à la moindre baisse de qualité ou interruption de flux. La scalabilité de l’infrastructure est par ailleurs fondamentale pour absorber le volume exponentiel de requêtes généré par ces essaims d’agents collaborant en permanence. Contrairement aux architectures historiques, ces pipelines unifiés agissent désormais comme le système nerveux central de l’entreprise, connectant instantanément l’ensemble des nœuds de la chaîne.
Construire une architecture Data orientée « Agents Supply »
L’ingestion et la standardisation : casser les silos (ERP, WMS, TMS)
La toute première étape véritablement cruciale pour réussir le déploiement de cette architecture nouvelle génération consiste à surmonter définitivement la fragmentation historique des systèmes d’information logistiques. Dans l’écrasante majorité des grandes entreprises mondiales, les données critiques sont encore enfermées dans des silos logiciels hermétiques et distincts : les progiciels ERP gèrent la facturation et les commandes, les systèmes WMS pilotent les stocks physiques entre les murs de l’entrepôt, tandis que les plateformes TMS orchestrent les expéditions routières ou maritimes. Pour espérer optimiser la chaîne de valeur dans son ensemble, l’agent autonome doit impérativement avoir accès à une vue unifiée et cohérente de toutes ces opérations disparates. L’ingénierie des données intervient très précisément à ce stade pour concevoir et maintenir des pipelines capables d’ingérer massivement ces informations hétérogènes, de les nettoyer méthodiquement et de les standardiser au sein d’un entrepôt de données centralisé performant. Ce travail de fond fastidieux permet de créer un langage commun indispensable, garantissant à l’agent IA de croiser efficacement une information de transport avec un niveau de stock de sécurité.
Gouvernance et sécurité au service de l’action automatisée
Bien au-delà de la pure ingestion technique des flux d’informations, la mise en place d’une politique de gouvernance des données industrielles stricte constitue le garde-fou indispensable au succès de l’automatisation cognitive à grande échelle. Confier les clés des opérations logistiques et financières à des agents artificiels exige des entreprises une maîtrise absolue de la gestion des permissions ainsi qu’une traçabilité littéralement sans faille. Les data pipelines déployés doivent donc intégrer nativement des règles de sécurité garantissant que les agents logiciels n’accèdent qu’aux seules données pertinentes pour leur périmètre précis, évitant ainsi tous les risques de manipulations ou d’hallucinations décisionnelles. Comme le soulignent très régulièrement les experts et directeurs conseil de Converteo lors de leurs missions d’accompagnement, la transparence totale des modèles est l’unique clé de l’adoption par les équipes métiers. Il est devenu impératif de pouvoir retracer facilement le cheminement logique d’un agent autonome, en identifiant précisément quelles données sources ont motivé le déclenchement d’une action. Cette traçabilité exemplaire rassure toutes les parties prenantes sur la fiabilité opérationnelle de cette forme d’intelligence.
L’émergence rapide de l’intelligence artificielle agentique marque indubitablement un tournant décisif et sans retour en arrière possible pour l’optimisation des chaînes d’approvisionnement, offrant des perspectives de productivité totalement inédites face à une volatilité de marché toujours plus agressive. Cependant, cette magnifique révolution algorithmique repose intégralement sur la résilience et la solidité de ses fondations. Il n’existera jamais d’agents autonomes réellement performants au sein des entreprises sans une ingénierie des données irréprochable, seule capable d’acheminer une information propre, fraîche et hautement sécurisée en temps réel. Le data pipeline industriel s’impose donc logiquement comme le moteur caché de cette profonde transformation.
Pour les organisations désireuses de conserver durablement leur avantage concurrentiel et de s’engager avec succès dans cette voie technologique prometteuse, la première étape logique consiste à réaliser un audit approfondi et sans concession de leurs flux de données actuels. Cartographier avec précision les silos d’informations, évaluer objectivement la fraîcheur des indicateurs clés et mesurer la robustesse des architectures informatiques en place permet de poser un diagnostic très précis avant tout grand projet de déploiement de ces nouvelles technologies autonomes.
N’attendez plus pour sécuriser vos investissements technologiques et moderniser vos opérations. Contactez dès aujourd’hui les experts spécialisés en Data Architecture et Supply Chain du cabinet Converteo afin d’évaluer avec eux la maturité de vos data pipelines. Nos équipes vous accompagneront pour concevoir une infrastructure sur mesure, parfaitement dimensionnée pour nourrir de manière optimale vos futurs agents autonomes et transformer vos défis logistiques en authentiques leviers de rentabilité durables.










