
Données de panel CPG : Pourquoi nettoyer ses datas avant d’entraîner un Small Model ?
L’intelligence artificielle transforme en profondeur l’industrie de la grande consommation, mais l’effervescence initiale autour des modèles de langage massifs laisse progressivement place à une approche plus chirurgicale. Les entreprises se tournent désormais vers les Small Models, des architectures plus légères, spécialisées et redoutablement efficaces lorsqu’elles sont appliquées à des cas d’usage précis.
Les distributeurs et les marques de grande consommation prennent conscience que l’entraînement d’algorithmes agiles sur leurs propres données propriétaires offre un retour sur investissement bien supérieur à l’utilisation d’intelligences artificielles génériques. Cette transition stratégique vers des modèles réduits permet de conserver la maîtrise intellectuelle des outils prédictifs tout en maîtrisant drastiquement les coûts d’infrastructure cloud.
Cependant, contrairement à leurs homologues géants qui s’appuient sur des volumes d’informations d’une ampleur planétaire, ces Small Models sont dépourvus de culture générale intrinsèque. Cette spécialisation les rend hypersensibles à la qualité de l’information qu’ils ingèrent, particulièrement lorsqu’il s’agit de données de panel CPG, réputées pour leur complexité et leur densité.
Par conséquent, une hygiène irréprochable de la donnée devient le prérequis absolu pour garantir la viabilité et les performances de vos initiatives technologiques. Explorons en détail pourquoi un nettoyage rigoureux et méthodique de vos bases de panel est une étape non négociable avant de lancer l’entraînement de votre prochain modèle prédictif.
L’impact critique de la Data Quality sur les Small Models
Small Models vs Big Models : une tolérance zéro à l’erreur
L’engouement actuel pour l’intelligence artificielle a d’abord mis en lumière les modèles de langage massifs, entraînés sur des volumes d’informations colossaux à l’échelle du web entier. Ces architectures géantes possèdent une caractéristique fascinante : elles parviennent à diluer les erreurs et les approximations dans leurs milliards de paramètres. Cependant, la donne est radicalement différente lorsque l’on aborde les Small Models, ou modèles réduits, qui se concentrent sur un domaine d’expertise très précis. Avec un nombre de paramètres restreint, chaque donnée d’entraînement acquiert un poids statistique disproportionné. Si vos informations de panel sont corrompues, biaisées ou mal formatées, le modèle n’a pas la profondeur nécessaire pour compenser cette faille. Sa compréhension fondamentale du comportement du consommateur sera immédiatement faussée. Ainsi, la corrélation entre la data quality et la pertinence d’un petit modèle est directe, implacable et ne tolère absolument aucune marge d’erreur sous peine de rendre l’algorithme totalement inopérant.
Le syndrome du « Garbage In, Garbage Out » décuplé
Dans le domaine de la science des données, il existe un adage célèbre et intemporel : ce qui entre détermine ce qui sort. Ce principe s’applique avec une violence décuplée lors de la préparation des données pour l’intelligence artificielle en grande consommation. Les professionnels de la data passent traditionnellement jusqu’à quatre-vingts pour cent de leur temps à nettoyer et structurer les bases de données avant même de commencer l’entraînement. Injecter des informations non vérifiées, bruitées ou incohérentes dans une architecture agile mène irrémédiablement à des prédictions aberrantes ou à des hallucinations statistiques. Un algorithme nourri avec des données désordonnées produira avec une grande assurance des recommandations stratégiques complètement erronées concernant vos parts de marché ou les tendances d’achat des shoppers. Ce phénomène détruit non seulement la valeur du projet technique, mais il anéantit surtout la confiance des équipes métiers envers les initiatives d’intelligence artificielle de l’entreprise.
Les spécificités et pièges des données de panel CPG
Hétérogénéité des sources et fragmentation retail
L’univers de la grande consommation se caractérise par une complexité et une fragmentation extrêmes des informations. Les données proviennent d’une multitude de canaux disparates : tickets de caisse physiques, transactions e-commerce, programmes de fidélité de divers distributeurs, et déclarations de panélistes aux profils socio-démographiques variés. Chaque source possède sa propre nomenclature, son format spécifique et sa fréquence de mise à jour. Cette hétérogénéité structurelle engendre des bases de données chaotiques où un seul et même produit de grande consommation peut exister sous une dizaine de références différentes selon l’enseigne. Entraîner un algorithme de machine learning sur ce paysage fragmenté sans procéder à une unification préalable constitue une erreur fondamentale. Le modèle se perdra dans cette jungle sémantique, incapable d’établir des connexions logiques entre des produits identiques vendus dans des réseaux de distribution différents, rendant toute analyse cross-canal totalement impossible.
Identifier les biais comportementaux et les erreurs de saisie
Au-delà des défis liés au formatage technique, l’information issue des panels de consommateurs est intrinsèquement soumise aux failles humaines. Les panélistes peuvent omettre de scanner certains articles, déclarer leurs achats de manière inexacte, ou même modifier artificiellement leurs habitudes de consommation du simple fait de se savoir observés. À ces biais comportementaux s’ajoutent les erreurs de saisie classiques ou les mauvaises classifications opérées par les fournisseurs de données. À titre d’exemple, une erreur non détectée dans un panel a déjà poussé une grande marque de boissons à surproduire une référence en déclin, simplement parce que les packs promotionnels étaient comptabilisés à tort comme des unités individuelles. Identifier, isoler et neutraliser ces biais comportementaux ainsi que ces anomalies de saisie est une étape absolument cruciale pour garantir que le modèle apprenne la véritable réalité du marché et non une illusion statistique générée par des erreurs de manipulation.
Les étapes incontournables de préparation pour la grande consommation
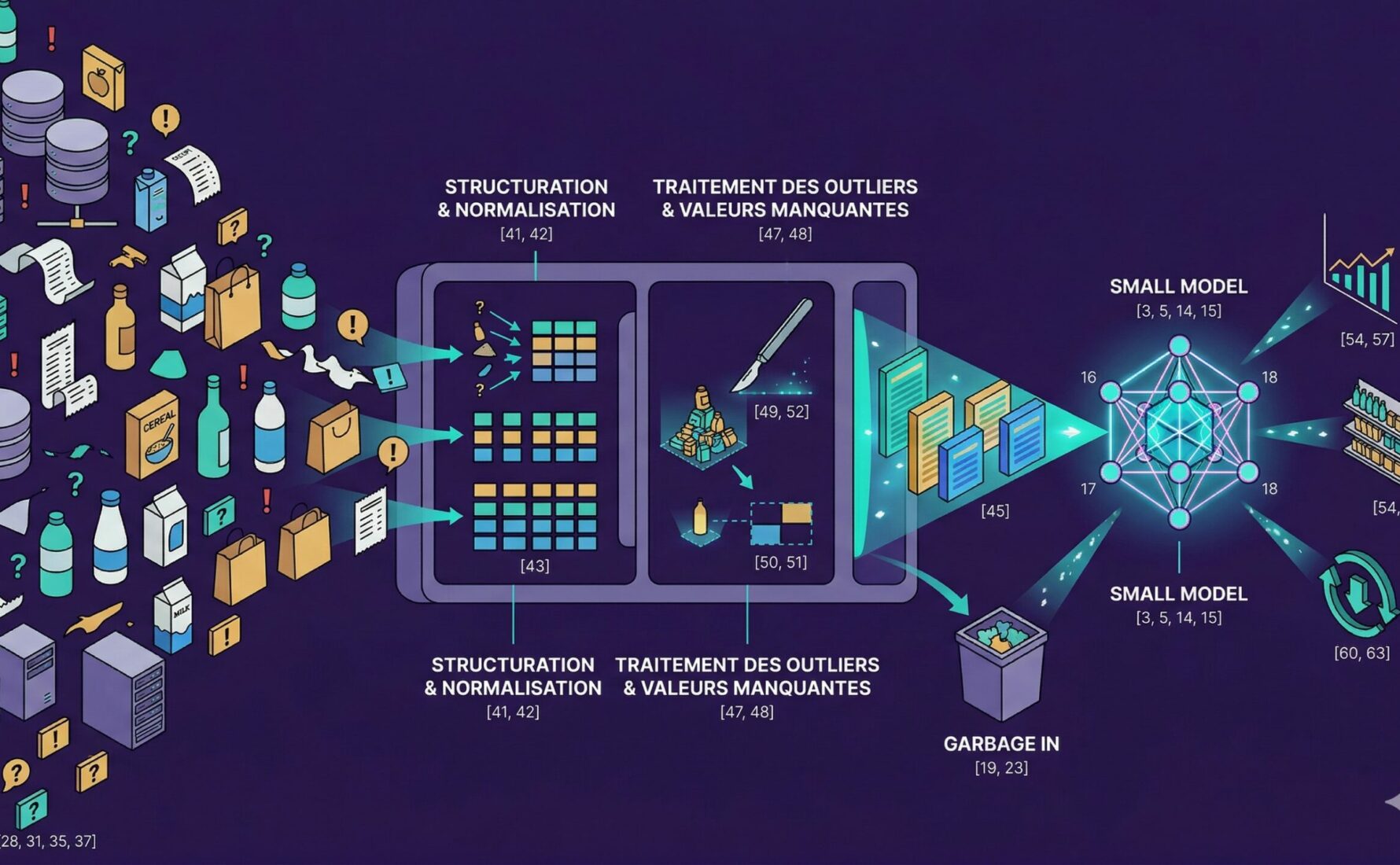
Structuration, normalisation et dédoublonnage des datasets
La première phase véritablement opérationnelle du nettoyage des données dans le secteur du retail consiste à imposer une architecture rigide et cohérente à l’ensemble des informations collectées. Il est impératif de normaliser les unités de mesure, d’aligner les catégories de produits à travers les différentes taxonomies des distributeurs et de procéder à un dédoublonnage systématique et rigoureux des enregistrements. Lorsque l’on manipule des milliers de références de grande consommation, s’assurer que la marque de distributeur d’un hypermarché ne soit pas confondue avec la nouvelle variante d’une marque nationale exige le déploiement d’algorithmes de correspondance sémantique avancés. Cette structuration méticuleuse permet de créer une source de vérité unique et consolidée. En offrant cette clarté absolue, vous fournissez à votre modèle réduit une fondation solide, dépourvue de toute ambiguïté, à partir de laquelle il pourra extraire des schémas de consommation réels et pertinents.
Traitement chirurgical des outliers et valeurs manquantes
Une fois la structure globale harmonisée, le travail de précision commence avec le traitement des anomalies résiduelles. Les valeurs aberrantes, par exemple un panéliste qui achèterait supposément une cinquantaine de flacons de shampoing au cours d’une seule semaine, faussent considérablement les moyennes et perturbent l’apprentissage des poids du modèle. De la même manière, les valeurs manquantes, qu’il s’agisse d’un champ démographique vide ou d’un prix de vente absent, désorientent l’algorithme. Plutôt que de supprimer purement et simplement ces lignes imparfaites, ce qui réduirait drastiquement le volume de la base d’apprentissage, les techniques avancées de data science privilégient l’imputation. Cette méthode consiste à combler les vides de manière intelligente et probabiliste en se basant sur des profils de consommateurs similaires, garantissant ainsi que le jeu de données conserve sa robustesse et sa représentativité face aux véritables dynamiques du marché.
Les bénéfices d’une donnée propre sur le ROI de vos modèles IA
Précision accrue des prévisions de ventes et d’assortiment
L’objectif ultime de l’optimisation d’un modèle réduit dans le secteur des biens de grande consommation réside dans sa capacité à fournir une intelligence directement actionnable. Lorsque les informations de panel sont d’une propreté irréprochable, l’intelligence artificielle devient capable de détecter des signaux faibles et des tendances de consommation authentiques, en s’affranchissant totalement du bruit statistique. Cette clarté analytique se traduit immédiatement par des prévisions de ventes d’une grande fiabilité et par des stratégies d’assortiment optimisées point de vente par point de vente. Les distributeurs comme les marques peuvent alors anticiper les fluctuations de la demande avec une précision chirurgicale, évitant simultanément les ruptures de stock qui génèrent de la frustration chez les clients, et les situations de surstockage qui immobilisent inutilement le capital et l’espace de stockage précieux.
Optimisation drastique des ressources de calcul
Au-delà de l’excellence prédictive, une donnée parfaitement saine offre un avantage technique majeur qui se répercute sur les finances de l’entreprise : l’efficacité opérationnelle. L’entraînement d’un petit modèle de langage ou d’un algorithme de machine learning agile sur une base de données épurée et de haute qualité requiert nettement moins de puissance de calcul et un temps de traitement considérablement réduit. Vous évitez ainsi les itérations sans fin et les ajustements laborieux pour tenter de corriger un modèle qui souffre en réalité de données d’entrée défectueuses. Cette optimisation rationnelle des ressources informatiques diminue de façon drastique les coûts d’infrastructure cloud liés aux opérations d’apprentissage. Par conséquent, vous accélérez le déploiement de vos projets d’intelligence artificielle, sécurisant un retour sur investissement rapide, mesurable et pérenne pour l’ensemble de vos initiatives technologiques.
En définitive, le succès du déploiement des Small Models dans l’industrie des biens de grande consommation repose intégralement sur l’excellence de la matière première qui les nourrit. Négliger l’étape cruciale du nettoyage des données constitue une erreur stratégique majeure qui hypothèque l’ensemble de votre transformation par l’intelligence artificielle.
En investissant l’expertise et les ressources nécessaires dans la structuration, la normalisation et la purification de vos panels de consommateurs, vous transformez une masse d’informations brute et chaotique en un véritable levier de compétitivité. C’est cette rigueur préparatoire qui sépare les expérimentations technologiques décevantes des véritables succès opérationnels.
Êtes-vous prêt à libérer le plein potentiel de votre patrimoine de données pour construire des modèles performants et fiables ? Les experts data et IA de Converteo sont à votre entière disposition pour auditer vos bases, déployer des pipelines de qualité robustes et vous accompagner de bout en bout dans l’entraînement d’algorithmes sur-mesure, parfaitement calibrés pour répondre à vos enjeux de croissance.










