
Anatomie de la plateforme data idéale

Cet article est le second d’une série sur les plateformes data – retrouvez le premier article Pourquoi se doter d’une plateforme data ? –, telles que Dataiku, Alteryx, KNIME, … Après avoir décrit en quoi ces plateformes peuvent être de réels accélérateurs de performances, décortiquons à présent leurs fonctionnalités.
Chez Converteo, nous sommes convaincus que la valeur apportée par ces plateformes provient à la fois :
- De leur aspect démocratique
- De leur capacité à s’intégrer au cœur de la chaîne de valeur de la donnée, hors collecte et activation :
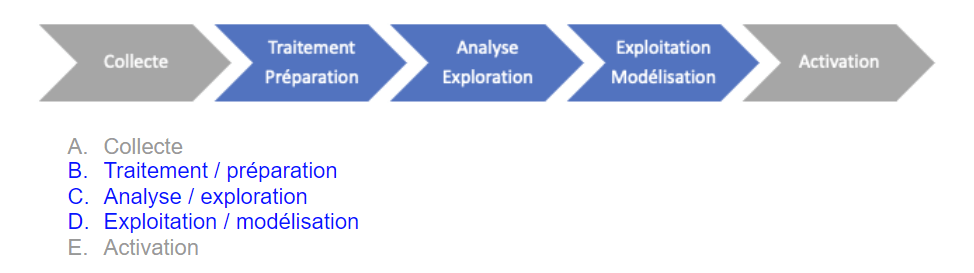
Nous nous proposons de décliner l’anatomie de la plateforme data idéale, en commençant par des prérequis non-spécifiques aux étapes de la chaîne de valeur de la donnée, puis en explorant le détail de ces étapes.
Les 5 vertèbres du squelette de la plateforme data idéale
- La plateforme idéale permet avant toute chose de se connecter en entrée à diverses sources de données (datawarehouse ou datalake, fichiers locaux, connexions SFTP ou API, etc.) et en sortie aussi bien à un espace de stockage qu’à d’autres briques d’exploitation de la donnée (Business Intelligence, CRM, Marketing Automation, etc.). Cet ensemble permet une intégration de bout en bout à l’écosystème data de l’entreprise
- La plateforme data idéale propose également une interface utilisateur moderne et intuitive, qui offre à l’utilisateur un vrai confort et lui permet de s’approprier rapidement l’outil, tout en gagnant un temps précieux dans la création et la gestion d’opérations sur la donnée, la navigation, le partage de projets, etc. (cf. exemples de « flux » ci-dessous).
[pdf-embedder url=”/app/uploads/2022/10/Exemples-de-workflows-Dataiku-SAS-et-Knime.pdf” title=”Exemples de workflows (Dataiku, SAS et Knime)”]
Fig.1 Exemples de workflowsDataiku, SAS et Knime - La plateforme permet à l’utilisateur de privilégier l’interaction visuelle (via clic-bouton, drag & drop), tout en permettant aux profils ayant les compétences de coder si besoin (en SQL, Python, R, etc.). Cela permet à toute la famille des profils data (Data Engineer, Data Analyst, Data Scientist, Machine Learning Engineer) d’utiliser un seul et même outil selon ses usages et préférences.
- En termes de “moteur”, la plateforme doit être capable de mettre à profit les meilleures pratiques actuelles dans l’utilisation et l’optimisation de la mémoire : elle doit pouvoir gérer des volumes de données importants de façon simple et performante, en étant adossée à un service existant (ex. BigQuery, Snowflake), en tirant partie d’un framework de calcul distribué (ex. Spark), ou encore en étant capable de se brancher sur des infrastructures dédiées, locales ou dans le cloud.
- Enfin, cette plateforme propose une gestion des accès utilisateurs simple, claire et personnalisable, ce qui permet la centralisation et une bonne distribution de l’accès à la donnée dans l’entreprise.
Une boîte à outils complète et accessible
Au coeur de la chaîne de valeur de la donnée, la plateforme idéale propose un ensemble de fonctionnalités essentielles aux activités des équipes data :
Traitement / Préparation
La plateforme idéale propose par défaut une grande variété d’opérations de base (filtrage, formatage, agrégation, jointure, union, …) et plus complexes (fenêtrage, pivot, géocodage, …). Elle permet également d’automatiser des scénarios de mise à jour de ces opérations, qui doivent pouvoir être déclenchés de manière temporelle (fréquence quotidienne, hebdomadaire, etc.) ou suite à un événement (à la détection d’un changement des données en entrée par exemple). La plateforme permet enfin de documenter chaque étape du traitement, par le biais de notes utilisateur et d’un espace dédié à chaque projet, le tout étant relié à un système de notifications.
Analyse / Exploration
Sur cette plateforme, il est possible de visualiser les données et le résultat d’analyses de manière immédiate. De même, il est possible d’explorer en un clic la distribution des valeurs d’une colonne d’un dataset, et d’observer des indicateurs statistiques de base (moyenne, médiane, écart-type, …).
Exploitation / Modélisation
La plateforme ne comprend pas seulement des fonctionnalités de transformation des données : elle propose également des modules de data science accessibles et complets, où il est notamment possible de créer des algorithmes de machine learning. La plateforme offre différents espaces de travail : notebooks, interface visuelle, avec la possibilité de passer du code (Python, R) au clic en permanence. On peut y réaliser des tests statistiques simples, complexes, ou personnalisés. Il est également possible d’y créer différentes versions d’un modèle, et de documenter chacune d’entre elles. Enfin, il est possible de mettre en production un modèle directement depuis la plateforme.
Et demain ?
A l’heure actuelle, la majorité des acteurs sur le marché des plateformes data (Dataiku, Alteryx, KNIME, …) n’investissent pas (encore ?) les extrémités de la chaîne de valeur de la donnée, que mettent à profit d’autres outils de l’écosystème data : centralisation des sources de données, création d’un référentiel client unique et d’une vue client 360, ou encore activation client sont pour l’instant l’apanage des Customer Data Platforms, Data Marketing Platforms, outils de marketing automation, …
Se pose donc naturellement la question de la manière d’interfacer ces différents outils, et du choix d’un outil en fonction d’un besoin. La logique sous-jacente de ladite question constitue l’élément central de notre sujet : c’est l’identification du besoin, des besoins d’une organisation, de manière précise et exhaustive, qui permettent de définir – quelle stratégie, quelle équipe, quel outil – la meilleure réponse à y apporter.
N’hésitez pas à nous contacter pour en savoir plus.
Auteurs :
- Emmanuel Noiraud, Consultant Senior Converteo
- Sébastien Zinn, Consultant Senior Converteo