
Converteo médaille d’argent d’une compétition de data-science sur la prédiction de la valeur des clients de la banque Santander
Kaggle est une plateforme permettant l’organisation de compétitions de machine-learning ouverte au plus grand nombre. Sa notoriété commence à s’étendre hors des cercles techniques depuis son rachat par Google en 2017. La diversité des thématiques abordées lors des compétitions (du comptage de phoques, à la classification de particules subatomiques, en passant par la prédiction du vainqueur de la NCAA ou l’analyse de sentiments) permet d’attirer des communautés et des spécialités différentes de la data science.
La compétition Santander Value Prediction, qui s’est déroulée du 19 juin au 20 Août, visait à prédire le montant de la prochaine transaction de leurs clients. Elle a regroupé 5193 compétiteurs réunis en 4591 équipe pour un total de 57 699 soumissions. L’équipe Converteo était constituée de 5 data-scientists issus de sa Communauté Data. Cette communauté en croissance regroupe les experts techniques en data-science et data-engineering du cabinet. Ils réalisent pour nos clients les missions de déploiement cloud mais aussi les travaux de statistiques et modélisation tels que le scoring d’appétence, la prédiction d’attrition, de valeur client ou de segmentation.
L’équipe Converteo s’est classée 168e (top 4%), à l’issue de la compétition, lui permettant d’obtenir une médaille d’argent (décernée au Top 5% lorsque la compétition dépasse 1000 équipes). Elle finit avec un RMSLE (Root Mean Squared Log Error) de 0,54576 à seulement +0,026 (+4,99%) des vainqueurs. Il est à noter que la forte participation est due tant à la volumétrie de la donnée qui permettait un traitement en local, qu’à la structure de la donnée plus accessible que l’analyse de texte, d’images, ou d’audio.
Pour tout client, qu’il soit une banque ou non, la valeur d’un client à différents termes est un indicateur clé afin de justifier les dépenses commerciales ciblées. En effet, à court et moyen terme, cet indicateur peut permettre d’appuyer le choix d’une action de rétention plus coûteuse – déclenchement d’un appel plutôt que d’un courriel par exemple. Lors de l’acquisition, connaître la valeur client à long terme (ou “lifetime value”) permet de rationaliser les dépenses d’acquisitions, que ce soit pour des enchères média en ligne, ou pour des offres commerciales lors d’un rendez-vous client.
Pourquoi participer au challenge
L’effervescence académique dans de nombreux domaines du machine learning conduit à un changement rapide de l’état de l’art. Malgré le nombre important de communautés en ligne, de blogs, et de conférences, il peut être difficile de rester à jour, et surtout d’avoir l’occasion d’essayer les nouvelles techniques sur un dataset. Un challenge offre à la fois l’accès à un dataset, mais aussi à une communauté travaillant sur le même sujet au même moment, permettant un partage des connaissances et des ressources incomparable avec le fonctionnement classique d’un projet.
Deuxièmement, cela permet d’avoir un classement objectif de sa performance technique sur un sujet. Tous les compétiteurs étant évalués de la même manière, seule la précision de la réponse sera évaluée.
La différence entre le conseil et la compétition
Participer à un challenge Kaggle peut être déroutant pour des consultants data scientists habitués à travailler sur des cas clients réels. D’autant que la compétition Santander Value Prediction s’est révélée atypique (même selon les critères de Kaggle) pour plusieurs raisons.
Des données anonymisées perturbant l’exploration
La donnée fournie par Santander présentait plusieurs particularités.
La première était d’ordre technique, avec un nombre de colonnes pour le dataset d’entraînement plus grand que le nombre de variables (4459 observations pour 4993 variables), et une matrice très creuse (96,8% de zéros).
La seconde est d’ordre métier : le nom de toutes les variables étant volontairement chiffré, aucune connaissance métier ne pouvait être utilisée afin d’améliorer les modèles. En effet, lors d’un projet de data science, grâce à un dialogue avec le client et à une compréhension analytique de son business, les consultants ajoutent de l’intelligence humaine aux données brutes en faisant du feature engineering. Cette étape traduit les connaissances métiers en variables supplémentaires qui alimentent le modèle de machine learning. Santander ayant anonymisé le nom des variables qu’il fournissait, l’équipe n’a pas pu enrichir les données de base avec cette surcouche métier.
Enfin la révélation d’un “data leakage”, c’est-à-dire la présence de la valeur à prédire dans le dataset à valider, a transformé l’interprétation de la donnée. En effet, l’apparition de répétitions faisant penser à des séries temporelles décalées a bouleversé la compétition en permettant la reconstruction partielle de la valeur à prédire lorsque les données d’un même client étaient décalées entre deux lignes (Figure 1). Ceci est dû à une technique classique du machine learning, appelée “data augmentation”, et qui consiste à fractionner son dataset afin de fournir plus d’exemples à l’algorithme.
Cependant, lors d’une compétition, il est possible de se servir cette technique pour reconstruire la variable à prédire (Figure 2). Le fait que cette information ait été rendue publique implique que pour réussir, les équipes doivent à la fois exploiter cette faille, mais aussi développer les algorithmes les plus fiables sur le reste des données. En effet, les données ne pouvant être reconstruites servent à départager les modèles des différentes équipes.
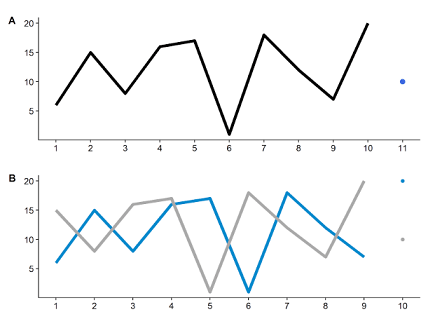
Figure 1 :
A. Série temporelle originale, avec les valeurs d’entraînement en tant que ligne et la valeur à prédire en tant que point.
B. Deux séries temporelles issues de la première. Si la valeur à prédire est la valeur suivante, il possible de la prédire pour la série bleue, car elle est présente en tant que 9e valeur de la série grise.
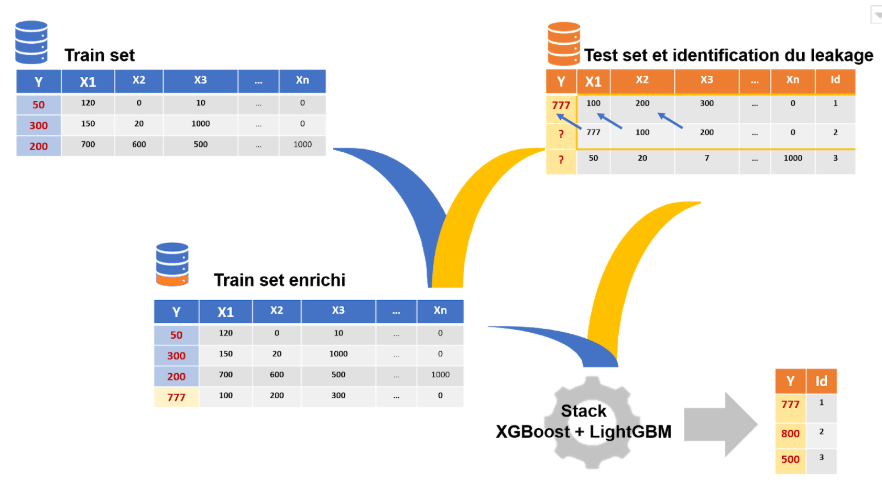
Figure 2 : Explication de notre méthodologie et utilisation du data leakage
Le périmètre d’une mission Kaggle est strictement délimité, alors qu’une mission de conseil comporte en général une large partie exploratoire
Lors de cette compétition, la question posée et le périmètre étaient clairement spécifiés : “utiliser ces données pour résoudre ce problème” nous a-t-on dit. L’avantage est que les candidats ont pu se concentrer tout de suite sur le code à produire. L’inconvénient est qu’on se prive potentiellement d’éléments clés : après tout, la personne qui a décidé du périmètre a pu omettre un détail important.
En réalité, une partie importante du travail chez un client consiste à enquêter, dialoguer avec les équipes et scanner les bases de données disponibles. La sélection des use cases et la délimitation du périmètre se fait en partenariat avec le client après une étude de faisabilité. Ce processus, bien que plus long, reste la meilleure façon de voir un projet aboutir. Dans une compétition Kaggle, c’est un travail qui est réalisé par les organisateurs, mais dans un contexte professionnel, cela fait partie de la mission du data scientist que de déterminer et formuler le problème business qu’il devra résoudre.
Utilisation des solutions publiques
Une compétition Kaggle est aussi une situation exceptionnelle dans le sens où elle amène de très nombreuses équipes à travailler sur un même projet. Si le code des participants n’est pas toujours public, de nombreux notebooks disponibles permettent de s’inspirer. Il est même nécessaire de consulter régulièrement les discussions et le code publié par les participants : on s’assure ainsi de ne rater aucune piste de réflexion. L’exercice pousse les candidats à se plonger dans des lignes de codes qu’ils n’ont pas écrites, à en tirer les idées intéressantes et à trouver les failles pouvant être améliorées, pour gravir les places du leaderboard. En somme, un très bon entraînement pour l’esprit critique.
Dans le cas précis de cette compétition, le leakage – dû à la technique de data augmentation exposée précédemment – d’une partie de la cible à prédire à été initialement identifié par un participant qui l’a rapidement exposé publiquement. Suivre le travail des concurrents représente donc un exercice du sens critique afin d’évaluer ce qui pourrait être intégré à son propre modèle afin de l’améliorer. Une réelle mission de data scientist requiert au contraire d’explorer seul les différentes méthodes de traitement de la donnée qui pourront répondre au problème. Lors d’une mission client, il faut donc garder à l’esprit les limites des modèles et les pistes qui peuvent encore être explorées, afin de présenter créer le modèle répondant le mieux à ses attentes.
Ce que l’on retire de la compétition
1. Être agile pour faire face aux perturbations du classement
L’équipe Converteo a travaillé sur de très nombreuses approches : plusieurs méthodes de sélection des variables, plusieurs algorithmes, plusieurs variables calculées ont été testées. Il était essentiel de d’essayer et combiner ces approches rapidement. C’est pourquoi la modularité du code a été salutaire. Au fur et à mesure que nous avancions, les différentes méthodes testées ont enrichi une librairie “Santander” – hébergée sur le Gitlab de Converteo – que nous avons construite pour la compétition. Les modules de cette librairie contiennent des fonctions de nettoyage de la donnée, de création de variables statistiques, de réduction de dimension, etc.
- D’éprouver facilement différentes combinaisons et d’identifier les meilleures
- D’injecter rapidement de nouvelles idées dans notre code lorsque nous voyions des choses intéressantes à essayer dans les notebooks publics
2. Compresser le signal et améliorer l’apprentissage par déconvolution du signal
Sans connaissance initiale sur la dépendance temporelle entre les colonnes, la première idée fut de chercher à réduire le nombre de variables par utilisation de techniques de déconvolution (tels que l’analyse en composantes principales et l’analyse en composantes indépendantes). D’autre part, les caractéristiques statistiques ont aussi été utilisées par l’entraînement de modèles, parmi elles, nous avons notamment utilisé le pourcentage de 0 dans la ligne, la moyenne des valeurs positives, les déciles, ou la déviation standard.
Une fois la structure temporelle mise à jour, les mêmes statistiques ont pu être calculées par blocs de colonnes décrivant la même série temporelle – que nous avons intuitivement choisi de considérer comme un même produit.
Notre méthode (et la différence avec les gagnants)
1. Reconstruction du dataset par utilisation du leakage
Le leakage présent dans les données et décrit plus haut permettait pour un certain nombre de lignes du fichier de validation de prédire exactement la valeur cible. Cependant, les notebooks publics indiquaient uniquement comment retrouver ces lignes, et incitaient ensuite à se contenter de prédire ces valeurs. Pour les lignes qui n’avaient pas “leaké”, seules des méthodes de prédiction triviales étaient suggérées publiquement.
A contrario, nous avons choisi d’utiliser les lignes du test pour lesquelles la cible était connue pour enrichir le nombre d’observations sur lesquelles nos algorithmes étaient entrainés (Figure 2). Cette méthode nous a permis d’obtenir un dataset d’entraînement de 12999 lignes, contre les 4459 initiales. De plus, une fois notre prédiction réalisée sur le fichier test, nous remplacions la prédiction par la valeur cible exacte, lorsqu’elle avait été retrouvée.
Le leakage, loin d’arrêter la compétition, a finalement eu pour effet de diminuer la taille du dataset pertinent pour l’évaluation. En effet, toutes les lignes reconstruites correctement par utilisation du leakage ne permettaient plus de distinguer les candidats, la compétition était donc évaluée sur les lignes restantes.
2. Stacking et gradient boosted trees
Le modèle entraîné sur ce jeu de données a été la combinaison – par stacking – de trois algorithmes.
Une première couche était constituée de deux algorithmes différents de gradient boosting. Cette famille d’algorithme applique une méthode combinant elle-même de nombreux algorithmes à la suite : chaque estimateur cherche à améliorer l’erreur du précédent, et la combinaison pondérée des prédicteurs donne une prédiction pour la valeur cible.
Afin d’arbitrer entre les prédictions faites par les deux algorithmes de gradient boosting de la première couche (nommément XGBoost et LightGBM), une deuxième couche contenant une régression linéaire attribuait un poids à chacune de ces deux prédictions, en fonction des erreurs constatées de chacun.
3. Comment améliorer notre modèle
Quelles sont les méthodes des gagnants de la compétition qui leur ont permis d’obtenir une RMSLE de 0,026 points meilleur à la nôtre ? En plus d’une approche similaire à la nôtre, leur équipe a utilisé les stratagèmes suivants.
- La recherche de blocs de variables appartenant à la même série temporelle a été l’une des clés de la victoire pour Giba et Lukas. Beaucoup d’équipes, dont Converteo, ont dépensé du temps de calcul afin de reconstituer un maximum de blocs de lignes et de colonnes, cependant l’équipe gagnante a certainement été celle qui est allée le plus loin dans l’exploration de ces groupes.
- La prise en compte du lien entre les différentes lignes dans le calcul de la cross-validation. Puisque le leak était causé par le fait que certaines lignes des jeux de données étaient d’autres lignes décalées dans le temps, il n’y avait pas seulement des groupes de colonnes, mais aussi des groupes de lignes, pouvant chacun représenter un client. En stratifiant la cross validation par “client”, on s’assurait que chaque client apparaisse dans les différents splits de la cross validation, et donc que l’algorithme entraîné disposait de données sur des clients variés.
- Le stacking d’un plus grand nombre de modèles. L’équipe gagnante a combiné les prédictions de pas moins de 113 modèles, avec un grand nombre de modèles étant entraîné de manière unique sur un groupe de variables. Cette piste privilégiant la puissance de calcul a d’ailleurs été retenue par un grand nombre de concurrents en tête du classement, dont Anatoly ou Sagol.
Dans le cadre d’un cas client réel, il conviendrait toutefois de challenger un tel modèle – plus performant, certes, mais également plus gourmand en puissance de calcul. Quels sont les gains entraînés par un modèle 5% plus précis ? Quels sont les coûts additionnels d’un tel modèle ?
Conclusion
La participation à cette compétition a permis à une partie de l’équipe data d’échanger de manière privilégiée sur un sujet technique. En s’appuyant sur la méthodologie agile pour le développement, et sur leurs connaissances techniques pointues, les consultants ont pu décrocher une médaille d’argent dans ce concours atypique, en exploitant la modularité de leur code pour faire face aux changements de classement jusque dans les dernières heures avant la clôture de la compétition.
Cette compétition a été l’occasion pour les consultants d’enrichir leurs connaissances sur les modèles de réduction de dimension, et sur la création de variables statistiques dérivées (feature engineering) afin d’améliorer les résultats de leur modèle.
Cela a été aussi l’occasion de valider la pertinence des techniques utilisées par nos consultants lors des missions sur la prédiction de la valeur client, qui fera l’objet d’un article à venir.
Les Data Scientists ayant contribué au Kaggle et à cet article sont, par ordre alphabétique : Quentin Bilbault, Najlaa Bouali, Vincent Constanza, Paul Deveau et Thomas Pilewicz. L’ensemble du projet a été coordonné par Jérémie Lévy, Partner en charge de la practice Data x Business Consulting de Converteo.