
Kaggle – Détection de la pneumonie dans les radiographies

Le challenge Kaggle RSNA pneumonia s’est tenu du 27 Août au 1er Novembre 2018. L’équipe Converteo, composée de quatre consultants data-scientists s’est classée 217e à l’issue de la phase 2 sur 1 445 équipes rentrées dans la compétition en phase 1.
Pourquoi et comment détecter la pneumonie ?
La pneumonie, infection respiratoire aiguë affectant les poumons, est l’une des causes majeures de mortalité infantile (16% des décès chez les enfants de moins de 5 ans, soit 920 136 enfants en 2015) (1) .
Le diagnostic de la pneumonie se fait classiquement en recoupant plusieurs examens. Lorsque la “respiration sifflante” est présente, il est nécessaire de procéder à une radiographie confirmatoire, et si besoin de tests approfondis comme la prise de sang (2).
La détection de la pneumonie, même pour des radiologues, reste une entreprise difficile sur la base de l’image seule (la radiographie étant souvent altérée par des complications pulmonaires). A cela s’ajoute le coût et parfois la difficulté d’accès aux spécialistes, pouvant réduire le dépistage de la maladie dans les régions en situation de désert médical ou celles en voie de développement.
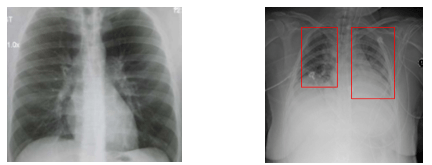
Figure 1 :
Cliché d’un patient sain à gauche et cliché d’un patient atteint de pneumonie à droite.
Les zones identifiées par les experts sont précisées en rouge
La possibilité de développer un outil accélérant la détection de cette maladie par proposition de régions “affectées” faciliterait l’accès aux soins de ces patients.
Qu’est-ce qu’un réseau de convolution ?
Une convolution est une opération mathématique. Pour la détection d’image, elle consiste à prendre un carré de pixels et à renvoyer une valeur numérique.
Un réseau de neurones basé sur les convolutions va consister à appliquer ces fonctions à la fois aux différentes parties de l’image mais aussi les unes à la suite des autres afin d’agréger les informations en gardant leur proximité spatiale.
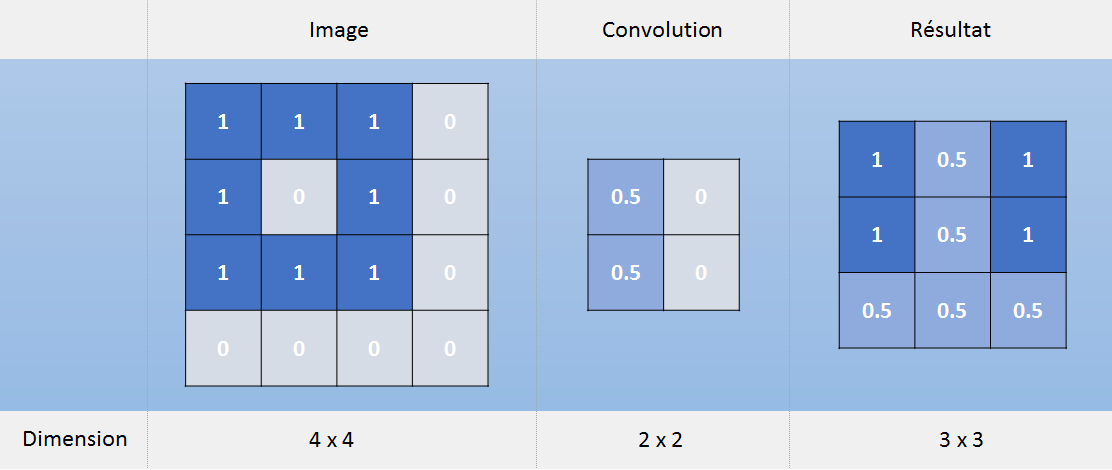
Figure 2 :
Calcul convolutionnel
L’exemple d’une convolution ci-dessus montre comment détecter des lignes verticales à gauche. De manière générale, les premières couches d’un réseau permettent de détecter des structures simples : lignes verticales, horizontales ou diagonales. La succession de plusieurs convolutions permettra de détecter des formes plus complexes, puis enfin des éléments de l’image tels qu’une oreille de chat ou un œil.
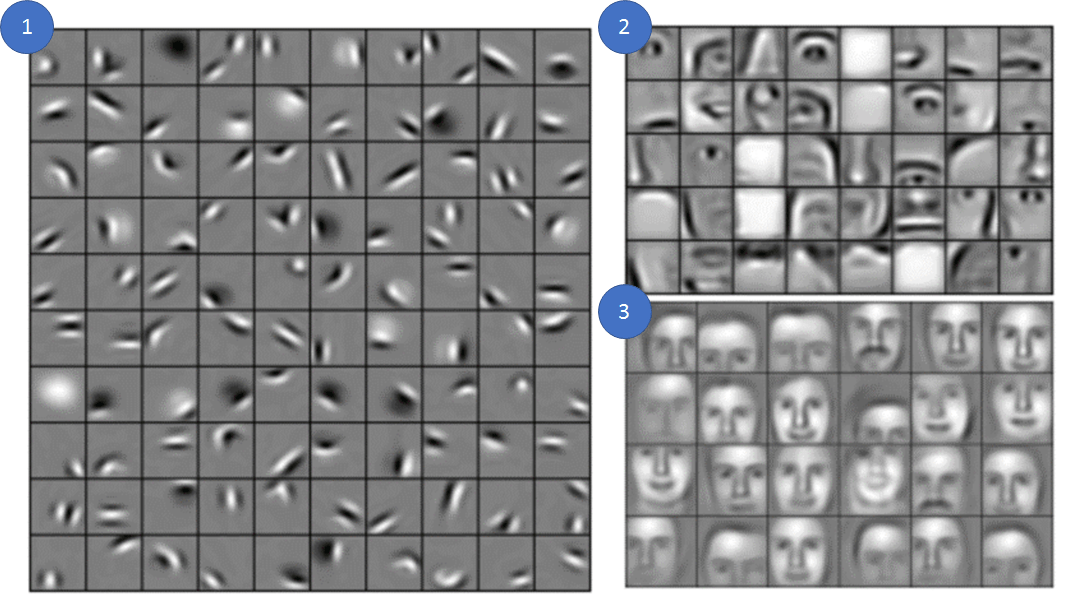
Figure 3 :
Exemple d’un CNN entraîné à reconnaître les visages (3)
Qu’est-ce que le transfer learning ?
Il s’agit d’une méthode de machine learning conduisant à ré-utiliser un algorithme entraîné à une tâche précise. Les coefficients régissant les interactions entre les couches servent en effet de mémoire au réseau pour effectuer la tâche de classification. Les premières couches étant dévolues à des processus simples comme vu dans précédemment, il peut être pertinent d’entraîner uniquement les couches finales. Cela permet l’accélération de la vitesse d’exécution, et l’amélioration des performances à la suite de l’entraînement sur un petit nombre d’exemples.
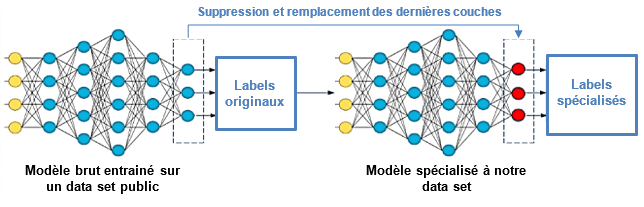
Notre approche ?
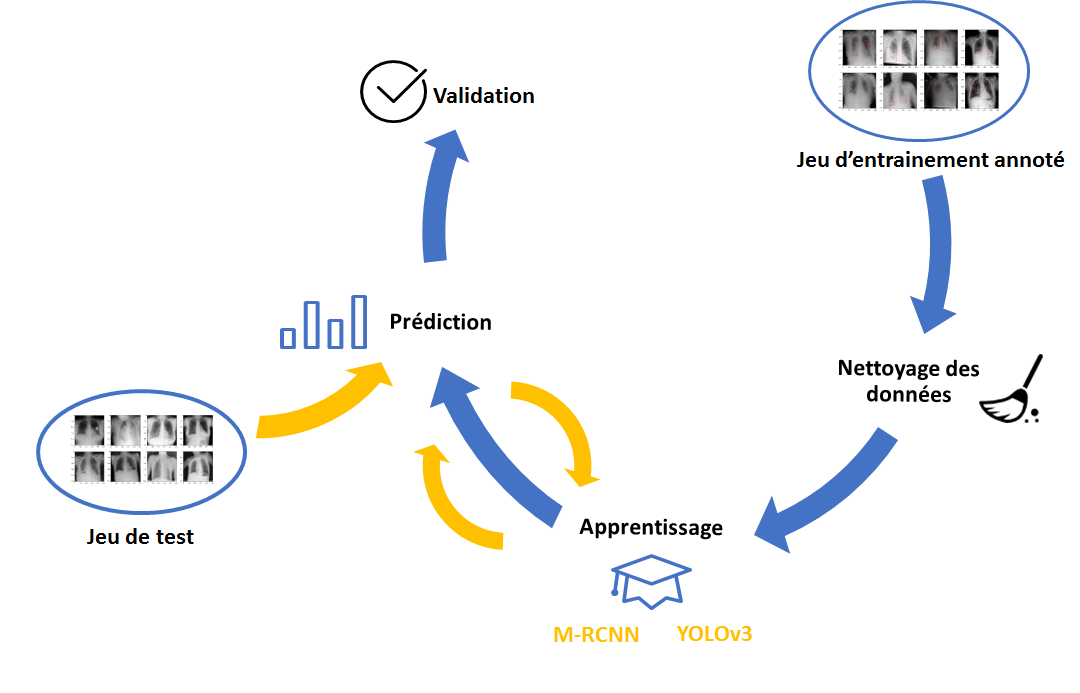
Nettoyage des données
L’entraînement d’un réseau de neurones, du fait du nombre important de calculs à faire en parallèle se fait de manière courante sur des carte graphiques. Ces ressources sont d’ailleurs souvent plus limitées en mémoire vive que ne le sont les processeurs. Une partie des ressources étant réservée au stockage des poids, il faut alors faire un choix entre le nombre d’images fournies simultanément (influant notamment sur la vitesse de convergence) et la résolution des images fournies.
De ce fait, les images sont souvent compressées afin de réduire leur taille à un carré d’une centaine de pixels de côté. Une erreur de cadrage conduit donc à une réduction de l’image disponible. Or, de nombreux clichés contenaient une bordure noire due à la numérisation de la radiographie pouvant parfois occuper une grande portion de l’image. L’un des premiers traitements appliqués a donc été de détourer par seuillage les images afin de ne conserver que les zones pertinentes à l’analyse.
Cela a eu pour effet la nécessité de développer des outils permettant de recalculer les positions et taille des boîtes avant et après conversion afin de pouvoir utiliser les annotations fournies par la plateforme et de soumettre les résultats dans le repère d’origine.
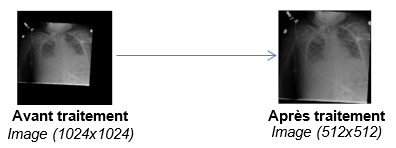
Figure 4 :
Détourage des radiographies par seuillage sur la ligne et/ou colonne
Apprentissage
La seconde partie du travail a consisté en l’entrainement de réseaux de neurones convolutifs et à comparer les performances de deux modèles principalement : YOLO et m-RCNN.
Alors que m-RCNN a pour finalité la segmentation de l’image en instances (attribution à chaque pixel de l’image d’une classe connue), YOLO se contente de créer une boite autour des objets. Les étapes d’up-sampling en fin de processus pour l’instanciation sont coûteuses, et en l’absence d’une annotation au pixel, nous n’avons pu mesurer d’amélioration de la prédiction. Au contraire, YOLO, initialement conçu pour offrir une grande rapidité dans la prédiction s’est révélé le plus performant lors de nos essais.
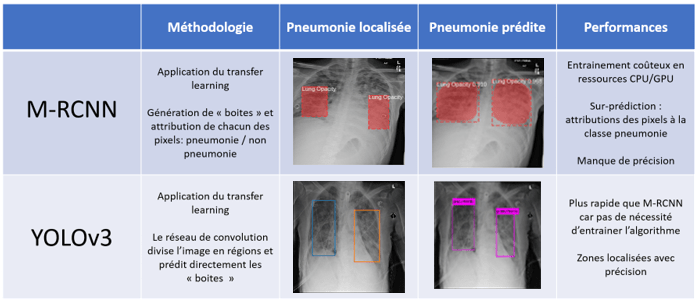
Figure 5 :
Tableau récapitulatif des deux algorithmes testés
Utilisation des métadonnées pour affinage de la prédiction
Le format d’imagerie médicale (DICOM), renseigne de nombreuses informations sur le patient comme son âge, son genre ou la position dans laquelle était le patient lors de la radiographie. Il est également possible de travailler sur les données de l’image en calculant son contraste, ou en cherchant la valeur des pixels maximum et minimum.
Ces “méta-données” permettent d’enrichir un dataset concernant le patient. Intégrer ces données pourrait permettre de corriger l’algorithme de détection dans des cas difficiles, notamment à un jeune âge alors que les os sont peu calcifiés par exemple. Nous avons donc utilisé l’intersection sur l’union des boîtes prédites avec la réalité comme cible à prédire pour un algorithme de gradient boosted trees, basé sur la confiance de la boîte prédite ainsi que les méta-données du patient.
Finalement, ce travail d’affinage ne s’est pas révélé performant. Après soumission des nouveaux résultats, notre score ne s’est pas vu augmenté. Un travail pertinent serait de construire une architecture de réseaux de neurones permettant la prise en compte de ces « nouvelles données » directement lors de classification de l’image.
Enseignements de la compétition pour les consultants Converteo
La méthode d’apprentissage profond (souvent appelée par son terme anglophone, Deep Learning) est largement utilisée pour la classification d’images, la traduction, ou la transcription de conversations.
Le score de cette compétition est calculé en recoupant les zones annotées par les experts médicaux (pneumonie réelle) et les zones calculées par les algorithmes des participants (pneumonie prédite). La compétition est d’une telle exigence que les résultats des meilleurs participants n’excèdent pas 20% de « recoupement » (on parle d’intersection sur l’union). L’équipe Converteo se place parmi le top 15% des challengeurs.
Les meilleurs compétiteurs ont utilisé l’architecture RetinaNet (7) qui est une architecture mono-structure contrairement à YOLO et qui essaie de concilier rapidité et précision de la prédiction.
Le point commun de RetinaNet, YOLO et mRCNN est leur entraînement préalable sur un jeu d’images en couleurs, donc composées de trois canaux (rouge, vert et bleu). Afin de rendre les images noir et blanc compatibles avec ces architectures, il a donc fallu récupérer matrice pour chacun des canaux, augmentant à la fois la mémoire nécessaire pour stocker une image et le nombre de paramètres du réseau pour l’analyser. Cette redondance pourrait être annulée dans le cas d’une architecture sur-mesure, au détriment de la capacité de transfer learning.
Lors de travaux de recherches sur une période plus longue que la durée d’une compétition, il serait intéressant de combiner cette réduction du poids avec l’incorporation des méta-données évoquée plus haut.
Conclusion
En participant à cette compétition, nous nous sommes intéressés au sujet aussi riche que passionnant qu’est l’imagerie médicale. En s’appuyant sur la méthodologie Agile pour la gestion de projet ainsi que sur nos connaissances techniques, nous avons pu toucher du doigt une problématique de demain : l’aide à la décision médicale.
Cette compétition a été une véritable opportunité d’enrichir nos compétences sur les modèles de Deep Learning, mais également sur les forêts aléatoires et arbres de gradients.
Aujourd’hui, nous pouvons profiter de compétences solides dans les technologies d’apprentissage statistiques : en effet, il y a quelques mois, l’équipe remportait la médaille d’argent à un challenge Kaggle qui visait à prédire le montant de la prochaine transaction des clients de la banque Santander.
Nous pourrons faire bénéficier les clients de nos savoir-faire lors des missions à venir. En effet, ce travail de reconnaissance d’images pourrait s’appliquer à des sujets marketing (détection de produits sur catalogues, reconnaissance de médias, etc.)
(1) World Health Organization, http://www.who.int/news-room/fact-sheets/detail/pneumonia
(2) American Lung Association, https://www.lung.org/lung-health-and-diseases/lung-disease-lookup/pneumonia/diagnosing-and-treating.html
(3) Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations, Honglak Lee, Roger Grosse, Rajesh Ranganath, Andrew Y. Ng
(4) Very Deep Convolutional Networks for Large-Scale Image Recognition, Simonian K & Zisserman A, ICLR, 2015
(5) Darknet: Open Source Neural Networks in C, Redmon J, http://pjreddie.com/darknet/, 2013
(6) Mask r-CNN, He K. et al, https://research.fb.com/wp-content/uploads/2017/08/maskrcnn.pdf, 2017
(7) Focal Loss for Dense Object Detection, Lin et al, 2017
Les Data Scientists ayant contribué au Kaggle et à cet article sont, par ordre alphabétique : Najlaa Bouali, Paul Deveau, Thomas Pilewicz et Louise-Marie Porcher. L’ensemble du projet a été coordonné par Jérémie Lévy, Partner en charge de la practice Data x Business Consulting de Converteo.