FMCG : Pourquoi privilégier les Small Models pour l’analyse des données de panel ?
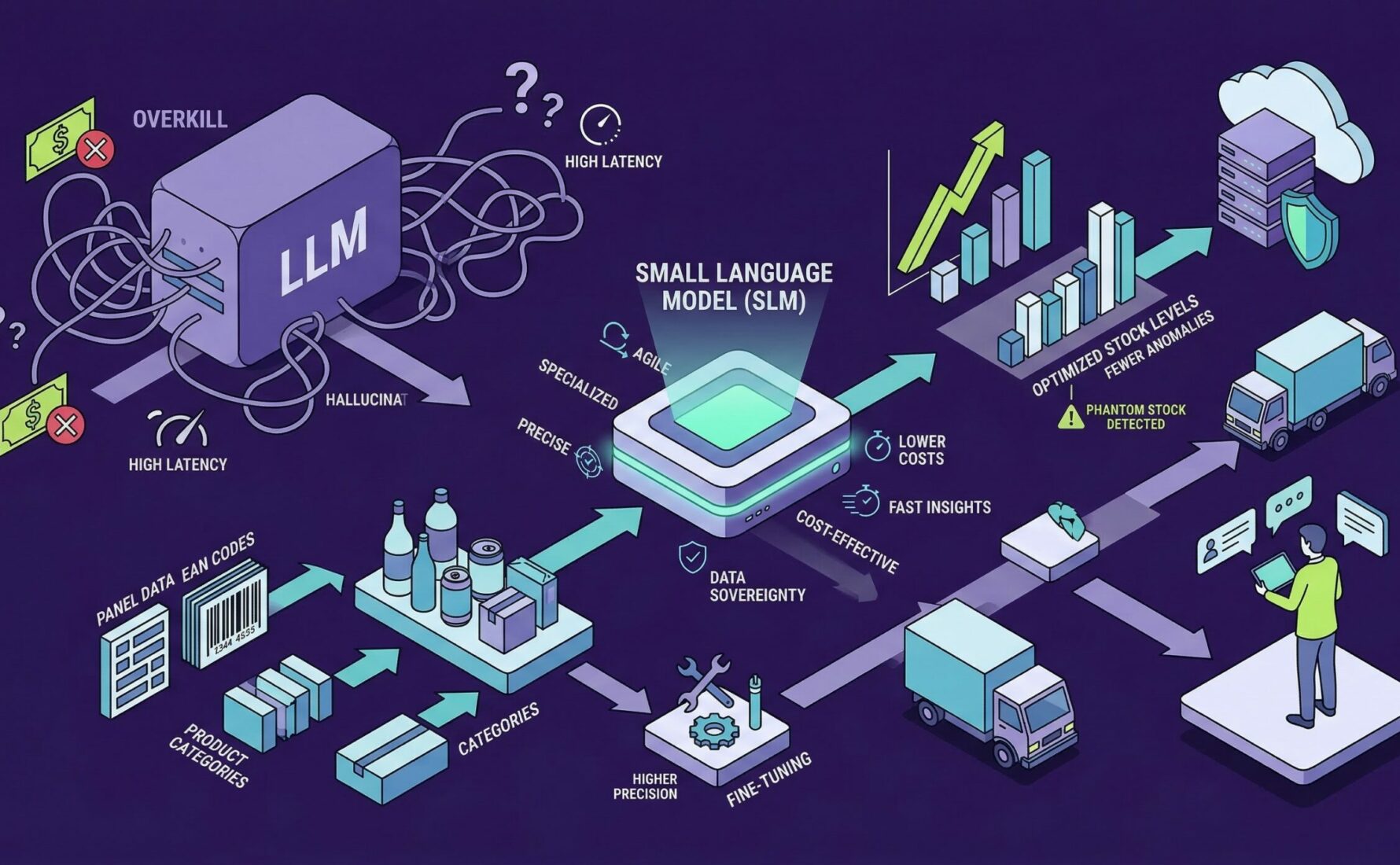
L’industrie de la grande consommation traverse une mutation technologique sans précédent où la donnée de panel constitue le pivot de la prise de décision stratégique. Longtemps cantonnées à des analyses descriptives a posteriori, les entreprises du secteur FMCG cherchent désormais à transformer ces flux massifs en insights prédictifs et prescriptifs en temps réel. Cette quête de réactivité a naturellement poussé les directions Innovation vers l’intelligence artificielle générative et les Large Language Models (LLM), perçus comme la panacée du traitement de l’information complexe. Cependant, l’usage de modèles aux centaines de milliards de paramètres révèle rapidement des limites structurelles lorsqu’il s’agit de manipuler des nomenclatures de produits et des comportements d’achat ultra-spécifiques.
L’analyse des données de panel, qu’elles proviennent de sorties de caisse ou de comportements de consommateurs, exige une précision chirurgicale que les modèles généralistes peinent parfois à atteindre sans un coût de traitement prohibitif. Face à cette réalité opérationnelle, une alternative plus agile et sobre émerge avec force au sein des écosystèmes data : les Small Language Models ou SLM. Ces modèles, dont la taille varie généralement entre un et sept milliards de paramètres, offrent une spécialisation métier indispensable pour décrypter les subtilités du retail. En privilégiant la profondeur de la connaissance sectorielle à l’étendue de la culture générale numérique, les Small Models s’imposent comme le choix de raison pour les acteurs du FMCG soucieux de leur efficacité.
Adopter une stratégie basée sur les Small Models permet de répondre à un triple impératif de performance, de coût et de souveraineté des données, des piliers fondamentaux pour tout cabinet de conseil expert en activation data. Contrairement aux géants du secteur qui nécessitent des infrastructures massives et des appels API coûteux, les SLM peuvent être déployés dans des environnements contrôlés, garantissant ainsi la souveraineté et de la confidentialité des données les plus sensibles. Cette approche favorise une intégration plus fluide dans les outils métiers des Category Managers, transformant la donnée brute en levier de croissance immédiat. L’enjeu n’est plus seulement de posséder la donnée, mais de disposer de l’intelligence la plus ajustée pour l’exploiter sans gaspillage de ressources.
Dans les lignes qui suivent, nous explorerons comment ces modèles compacts surpassent leurs homologues géants dans l’analyse granulaire des données de panel. Nous verrons que la réduction de la taille du modèle, loin d’être une perte de compétence, constitue en réalité un gain de pertinence grâce aux techniques de fine-tuning appliquées aux spécificités du secteur de la grande consommation. De la réduction de la latence à l’optimisation des coûts d’inférence, découvrez pourquoi la frugalité numérique devient le nouvel étalon de la performance pour les leaders du FMCG. Cette transition vers des modèles spécialisés marque le passage d’une IA de démonstration à une IA d’exécution, capable de transformer durablement la gestion des assortiments et des promotions en magasin.
La fin de l’hégémonie des LLM pour les données structurées du retail
L’enthousiasme initial pour les modèles de langage massifs a souvent occulté une réalité technique majeure : la démesure algorithmique n’est pas synonyme de pertinence métier. Dans le secteur FMCG, les données de panel se caractérisent par une structure rigide, composée de codes EAN, de libellés produits abrégés et de hiérarchies de catégories complexes qui diffèrent d’un distributeur à l’autre. Utiliser un modèle entraîné sur l’intégralité du web pour classifier une nouvelle référence de boisson gazeuse revient à utiliser un marteau-piqueur pour enfoncer une épingle. La complexité interne des LLM génère souvent des hallucinations ou des approximations inacceptables lorsqu’une erreur de classification de 1 % peut entraîner des pertes sèches de plusieurs millions d’euros en stocks mal pilotés.
Au-delà de la précision, la question de la sécurité des informations se pose avec une acuité particulière pour les industriels de la grande consommation. Les données de panel sont le fruit de partenariats stratégiques et contiennent des secrets commerciaux liés à la performance des innovations ou à la réactivité promotionnelle. Envoyer ces flux d’informations vers des serveurs tiers via des API de modèles propriétaires expose l’entreprise à des risques de fuites ou de réutilisation des données pour l’entraînement de futurs modèles concurrents. Les Small Models offrent ici une alternative de sécurité majeure puisqu’ils sont capables de fonctionner on-premise ou dans des instances cloud privées totalement isolées, protégeant ainsi l’avantage concurrentiel de la marque.
Les avantages comparatifs des Small Models en FMCG
La supériorité des Small Models dans l’univers du retail repose sur leur capacité de spécialisation extrême via le fine-tuning. En entraînant un modèle de 3 ou 7 milliards de paramètres sur un corpus spécifique de tickets de caisse et de nomenclatures de produits, on obtient une précision de classification supérieure à celle d’un modèle généraliste cent fois plus volumineux. Pour un Category Manager, cela se traduit par une capacité de l’IA à comprendre instantanément que deux libellés différents désignent en réalité le même produit en promotion, permettant une réconciliation parfaite des stocks. Les tests de performance montrent que sur des tâches de NLP spécifiques au retail, un modèle compact bien entraîné réduit le taux d’erreur de segmentation de près de 15 % par rapport à une solution générique.
L’aspect économique constitue le second levier de cette révolution de l’IA frugale pour le secteur FMCG. Les coûts d’inférence, c’est-à-dire le coût de chaque requête adressée au modèle, sont drastiquement réduits avec les Small Models, souvent divisés par un facteur dix ou vingt. Pour une entreprise traitant des millions de lignes de panels chaque semaine, l’économie réalisée sur les coûts de calcul devient un argument décisif pour la rentabilité du projet IA. De plus, la latence est quasi inexistante, ce qui autorise un pilotage dynamique de la performance commerciale en temps réel. Cette agilité technique permet de passer d’une analyse statique mensuelle à une réactivité immédiate, renforçant l’avantage compétitif des marques.
Cas d’usage : Optimiser la lecture des sorties de caisse et la supply chain
L’application concrète des Small Models se manifeste particulièrement dans l’automatisation de la détection d’anomalies au sein des rayons de la grande distribution. En analysant les flux de sorties de caisse en continu, un SLM spécialisé peut identifier des ruptures de stock invisibles dans les systèmes classiques de gestion, comme les « stocks fantômes » où le produit est physiquement en réserve mais absent du linéaire. Grâce à sa compréhension des cycles de vente locaux, le modèle alerte les équipes terrain avec une pertinence accrue, évitant les fausses alertes qui polluent le quotidien des chefs de rayon. Cette précision opérationnelle garantit une disponibilité produit optimale, un facteur clé de fidélisation dans un marché FMCG ultra-concurrentiel.
Enfin, les Small Models révolutionnent la personnalisation des insights pour les décideurs du siège et les responsables de comptes clés. Au lieu de naviguer dans des tableaux de bord statiques et complexes, les collaborateurs peuvent interroger leur base de données de panel en langage naturel via une interface simplifiée pilotée par un SLM. Le modèle, parfaitement aligné avec le vocabulaire interne de l’entreprise et les indicateurs de performance spécifiques au retail, génère des synthèses actionnables en quelques secondes. Cette démocratisation de l’accès à l’intelligence data permet de réorienter les budgets marketing et les stratégies de pricing avec une finesse inédite, assurant une croissance durable et maîtrisée pour les marques de grande consommation.
En conclusion, privilégier les Small Models pour l’analyse des données de panel n’est pas un renoncement technologique, mais une optimisation stratégique majeure pour le secteur FMCG. Ces modèles compacts offrent une précision métier inégalée, une sécurité des données renforcée et une efficacité économique indispensable au déploiement de l’IA à grande échelle. Pour transformer vos flux de données en leviers de performance concrets et rentables, l’adoption d’une approche spécialisée et frugale constitue désormais le standard de demain. Les entreprises qui sauront intégrer ces outils agiles au cœur de leurs processus décisionnels disposeront d’un avantage décisif pour dominer leur catégorie et répondre aux attentes changeantes des consommateurs.