
Google Analytics 4 & écarts – Une méthode d’analyse


Pierre Adrien Lair, lead analytics chez Converteo, est expert des sujets Data & Analytics. Il accompagne nos clients dans la collecte et l’analyse de données issues de l’écosystème digital marketing.
Vous avez enfin décidé d’utiliser Google Analytics 4.
Vos rapports sont construits et personnalisés à travers l’utilisation des Collections, comme évoqué dans notre précédent article. Le temps du pilotage et de l’analyse est désormais venu.
Soudainement, vous êtes confrontés à la hantise de l’analyste : vous commencez à croiser vos chiffres, à les challenger entre différentes sources, différentes périodes, et vous ne retombez pas sur vos pattes : vous avez des écarts !
Nous parlons de différents écarts sur les metrics selon le contexte d’analyse :
- Ecarts entre Google Analytics 4 et Universal Analytics
- Ecarts entre Google Analytics 4 et BigQuery
- Ecarts entre Google Analytics 4 et un autre outil de collecte : Media (Google Ads, Search Console, Meta), Analytics (Piano), Testing (AB Tasty, Kameleoon), Consent Management Platform (Didomi) …
- Ecarts entre Google Analytics 4 et un outil de visualisation : Looker Studio, Tableau
- Ecarts au sein de l’interface Google Analytics 4 : entre les rapports et Explore
- Ecarts entre deux propriétés Google Analytics 4 : client-side et server-side
L’objectif de cet article est de fournir une méthodologie pour réagir sereinement face à des problématiques d’écarts Je vais également essayer d’illustrer avec quelques exemples types, qui je l’espère pourront vous débloquer si vous me lisez.
L’approche est universelle et se déroule en 3 temps : caractériser, expliquer, résoudre. Avec un enjeu : éliminer les explications non nécessaires du phénomène constaté.
Etape 1 : Caractériser l’écart
C’est l’étape la plus importante et la plus sous-estimée : avant de démarrer une analyse d’écart, il convient de maîtriser ses définitions : la documentation – quand elle est à jour – est votre meilleure alliée. 80% des problématiques d’écarts que je rencontre se résolvent par la compréhension des définitions.
Avec l’expérience, j’ai abouti à une classification des écarts en deux grands types : sémantique ou structurel.
L’écart est sémantique
Je nomme écart “sémantique” un écart sur une métrique (ou une combinaison metrique / dimension) expliqué par son concept et sa définition même.
Cette classe d’écart se retrouve notamment quand il s’agit d’expliquer des écarts entre Google Analytics 4 et un autre outil. L’analyste doit se poser cette question : est-ce que mes définitions sont les mêmes entre les outils ? La réponse est souvent la même : non !
On retrouve néanmoins deux cas typiques : les metrics sont nommées différemment entre les outils, les metrics sont nommées identiquement – ce qui est vecteur de confusion.
Cas 1 : Des concepts différents obéissent à des règles de calcul différentes
C’est assez évident, mais on ne compare pas des choux et des carottes 🥕.
Voici quelques exemples :
Exemple : “J’ai des écarts entre mes clics et mes sessions entre Google Ads et GA4”
➡️Ce sont deux concepts différents, et Google les détaille très bien dans cet article
Pourquoi les clics Google Ads et les sessions Analytics ne correspondent pas dans vos rapports
Exemple : “Mon Taux de Rebond et mon no-choice rate ne correspondent pas entre GA4 et ma CMP”
➡️Là encore, nous avons deux concepts différents, sur lesquels Didomi a fait un focus
Exemple : “J’ai plus de session que d’évènements session_start dans GA4”
➡️Deux concepts différents, même s’il est tentant de les rapprocher. La définition d’une session dans GA4 est une estimation du nombre de ga_session_id. L’évènement session_start est lui crée automatiquement par la librairie cliente. Même si on pourrait s’attendre à avoir le même nombre de session_id et de session_start, ce n’est jamais le cas :
- Trop de session_start : ce cas (rare) a déjà été constaté quand un utilisateur démarre plusieurs sessions dans plusieurs onglets, que la librairie gtag a parfois du mal à gérer
- Absence de session_start : ce cas (commun) trouve différentes explications parmi :
- La période choisie inclus une session mais pas le session_start associé – notamment pour les sessions qui ont passé minuit
- Des audiences triggers sont mis en place – créant notamment du (not set) à gogo
- Les tags d’événements gtag / ga4 s’exécutent avant appel à la configuration
- Le consent mode advanced est mis en place et le session_start d’une session non consentie n’est pas rapproché avec la session après consentement
- Le setup server-side, sous certaines conditions, ne régénère pas de session_start pour les utilisateurs en reprise de session (navigateur ouvert)
Cas 2 : Des concepts similaires avec des règles de calcul différentes
C’est toute la subtilité : des choses nommées pareilles peuvent être différentes. Voyons quelques exemples communs.
Exemple : “Mes conversions sont différentes entre GA4 et Google Ads”
➡️Selon la configuration, les conversions peuvent obéir à des règles de comptage différentes (dédupliquées ou non). Attention également au modèle d’attribution associé : une attribution à une source d’acquisition de la session est en last clic indirect dans GA4, et en data-driven dans Google Ads.
Tout cela est expliqué dans la documentation Google : Comparer les métriques de conversion Analytics et Google Ads.
C’est aussi un des enjeux du renommage des Conversions en Key Events dans GA4.
Exemple : “Mes audiences sont de taille différente entre GA4 et Google Ads”
➡️On peut s’attendre à retrouver à l’identique une audience créée dans GA4 dans Google Ads. Si ce n’est pas le cas, je vous invite déjà à évacuer les différentes hypothèses proposées par Google dans sa documentation :
- [GA4] Why your audiences may not be populating in Google Ads
- [GA4] Troubleshoot importing Google Analytics 4 or Firebase audiences into Google Ads
On retrouve notamment ce cas depuis la mise en œuvre du DMA qui crée des implications sur le partage d’informations entre les outils.
Exemple : “Je n’ai pas le même nombre de sessions entre GA4 et BigQuery”
➡️Comme évoqué plus haut, les sessions sont estimées dans l’interface GA4, notamment avec l’algorithme HyperLog++. BigQuery, de son côté, restitue la collecte des ga_session_id bruts.
Si vous voulez rapprocher les résultats vous pouvez utiliser la requête suivante qui est évoquée ici

L’écart est structurel
J’appelle structurel un écart qui s’explique (ou se constate) par ses différentes composantes.
Pour valider qu’un écart est structurel, la première chose à vérifier est de valider le périmètre de comparaison de cet écart entre une source A et une source B :
- Les plages de dates doivent être identiques
- Le périmètre entre les chiffres analysés doit être identique :
- Domaines de collecte
- Méthode de collecte (client-side, server-side, measurement protocol)
- Règles de déclenchement selon le consentement
- Application de filtres
- Application de segments
Des chiffres constatés comme différents doivent l’être sur une base comparable.
Nous avons donc catégorisé nos écarts (sémantiques / structurels), nous pouvons désormais chercher à les expliquer.
Etape 2 : Expliquer l’écart
Une fois l’écart caractérisé, nous rentrons dans une phase d’explication qui va se dérouler en 4 phases :
- Exploration de l’écart
- Reproduction de l’écart
- Formulation d’hypothèses
- Quantification
Phase 1 : Exploration de l’écart
Explorer un écart c’est avant tout se poser les bonnes questions !
Pour construire son analyse et ses différents segments voici les questions que j’aime me poser :
- L’écart entre ma source A et ma source B est-il constant dans le temps ?
- Ajouter une source C permet-il d’éclairer l’écart ?
- L’écart est-il identique dans les différents supports de restitution (Collections, Explore, Looker Studio…) ?
Exemple : “J’ai des chiffres différents à différents endroits de l’interface GA4, et également dans l’API”
➡️Bien que l’on pourrait effectivement s’attendre à avoir des chiffres uniformes lorsque l’on interroge l’outil, ce n’est pas toujours le cas : Sampling, Modelling différents… Google applique des méthodes de calculs et d’appels des données multiples. Certaines sont référencées dans la documentation : [GA4] Reporting surfaces comparison
- D’autres metrics sont-elles affectées par l’écart ?
- L’écart est-il réparti uniformément entre mes différentes dimensions ?
Exemple : “J’ai beaucoup de (not set) dans mes rapports de localisation”
Ou sa variante “J’ai une hausse du trafic US dans mes rapports”
➡️L’application du browser / OS sur une metric peut apporter des explications autour de Safari et du Private Relay ; lire Why Geography is wrong in GA4 ; Apple’s Safari 15.5: Impact on Geolocation Analytics
A noter également que dans GA4 la dimension “Country” est au User et non pas à la Session.
- A la plus petite granularité : combien de data points causent l’écart ?
Ainsi, si 10 sessions expliquent 90% d’une hausse de pages vues, alors il se peut que vous ayez subi des bots.
Phase 2 : Reproduction d’exemples explicatifs de l’écart
Pour expliquer un écart, il est essentiel d’isoler des exemples symptomatiques de cet écart. Mon conseil est de réduire le scope d’analyse au maximum : en limitant les dates, en appliquant un maximum de dimensions pour isoler et construire ses segments.
Ensuite, je vous conseille d’analyser et reproduire les parcours de ces visiteurs :
- Dans BigQuery en reprenant le client_id / session_id
- Dans GA4 si vous avez collecté un identifiant unique en paramètre
- Dans les rapports “User Activity” de GA4, accessibles via clic droit > View Users > User Explorer sur vos segments
Phase 3 : Formuler les hypothèses d’explication
En reprenant tous les exemples micro que vous avez identifiés, vous devez désormais être en capacité de formuler des hypothèses explicatives à vos écarts ; idéalement : vous identifiez un pattern.
Exemple : “J’ai une chute des sessions depuis le DD/MM”.
➡️ Après avoir isolé l’heure, voire la minute de la chute ; confrontez là à des éléments exogènes : Mise en prod dans Google Tag Manager, mise en prod IT, Apparition d’une release côté Google
A ce titre, les conséquences de la mise en place du DMA et l’activation des user-provided data sont des causes d’écarts récentes observées.
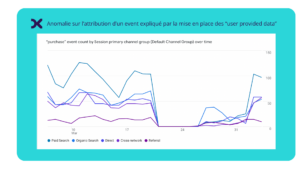
Phase 4 : Quantifier le % d’écart expliqué
Tracez vos hypothèses issues d’exemples sur l’ensemble de la plage de dates concernée par l’écart.
Dans les cas simples ; une hypothèse explique 100% de l’écart.
Malheureusement, un écart est majoritairement multi-facteurs : ce qui engendre mécaniquement une analyse plus coûteuse en temps.
Etape 3 : Résoudre l’écart
Maintenant que l’écart est identifié, des recommandations et modifications doivent être mises en place pour tenter de le résoudre. Je vous transmets les recommandations générales que j’ai l’habitude de retrouver :
- Mauvaise valorisation des variables dans le dataLayer
- Erreurs dans la création de règles de déclenchement
- Erreurs dans la gestion du consentement
- Variables obligatoires non déclarées dans le tag
Exemple : “je n’ai pas de valeur associée à mes transactions”
➡️En reprenant la documentation officielle, il est mentionné qu’il est obligatoire d’avoir une currency et une value avec son événement purchase.
- Configuration du data stream
Exemple : “j’ai des hits de page vue en double”
➡️Cela peut être causé par le paramètre “ignore duplicate instances of on-page configuration” tel que mentionné ici.
Exemple : “j’ai des évènements inconnus qui apparaissent soudainement”
➡️Parmi les explications standardes : création / modification d’évènements, création d’audience trigger.
- Configuration de la propriété
Exemple : “j’ai un nombre anormal de users”
➡️L’application du modeling (consent mode) ou de la déduplication des users via la Reporting Identity peut être une cause
Bien évidemment, il reste des cas où, après application de la méthodologie, aucune hypothèse n’est satisfaisante ; dans ce cas, cela peut être dû à une erreur côté outil et il convient de se rapprocher de son reseller (pour les clients 360) pour mener une enquête approfondie avec les équipes dédiées chez Google.
La méthodologie appliquée : les écarts d’attribution Universal Analytics et Google Analytics 4
Question : “Mon attribution n’est pas comparable entre Universal Analytics et GA4”
C’est un sujet compliqué car ayant attrait au ROI des campagnes médias.
Appliquons notre méthodologie pour essayer d’y répondre.
Analyse sémantique
Hypothèse 1 :
Certaines métriques sont nommées de la même manière entre GA4 et Universal Analytics mais obéissent à une définition différente. Cela est notamment détaillé dans l’article de Google : Comparer les metriques : GA4 et UA.
Hypothèse 2 :
Quelles dimensions analysez-vous ? Les dimensions “Source / Medium” ne sont pas les mêmes que les dimensions “Session Source / Medium”.
Google le détaille dans l’article suivant : “Scopes of traffic-source dimensions”. Charles Farina également dans son article : The Traffic Source Challenge in GA4. Si j’essaye d’être le plus synthétique possible : les dimensions regroupées dans l’onglet “Attribution” ont une application data-driven qui se croise avec des conversions (ou “key events”) ; les dimensions à la session s’analysent à ce scope, tel qu’on avait l’habitude de le faire dans Universal Analytics.
Analyse structurelle
Hypothèse 3 :
Si vous rencontrez beaucoup de “unassigned”, cela peut être lié aux délais de processing liés à la Data Freshness : nous constatons que des données peuvent être réattribuées jusqu’à 48h après la collecte initiale.
Exploration et Reproduction des écarts
Hypothèse 5 :
Si vous constatez un taux de (not set) trop important sur vos campagnes, il peut y avoir plusieurs pistes liées notamment au triggering de vos tags. Celles-ci sont largement évoquées dans l’article d’Analytics Mania auquel je vous réfère
Hypothèse 6 :
Vérifier comment se comporte une session SEA à plusieurs pages entre Universal Analytics et GA4. Sur un site en Single Page Application, des problématiques de Rogue Referral pouvaient impacter vos métriques s’ils n’ont jamais été résolus ; là où GA4 gère ce phénomène différemment.
Hypothèse 7 :
Vérifier que les mécanismes de reconnaissances automatisés des campagnes sont OK : linking des comptes Google Ads, Partage du consent mode avec les différents services Google. C’est le b.a.-ba mais une erreur de configuration peut vite arriver.
Pour expliquer l’écart côté Google Ads, je vous réfère aussi à cet article : Drop GAds traffic and Consent Mode V2: all my conclusions
Formulation & Quantification
Hypothèse 8 :
Le volume de session et l’attribution associée n’est pas comparable entre les outils à cause de la structure des définitions.
Ainsi, dans GA4, un changement de source / medium / campaign dans un intervalle de 30 mn (selon les configurations standards) ne redémarre pas une session, au contraire d’Universal Analytics.
Grâce à une requête BigQuery qui compte le nombre de sessions multi-touchpoints dans un intervalle réduit, il est ainsi possible d’estimer l’impact de cette définition sur votre total.

Résolution
Hypothèse 6 :
Après enquête, si vous avez malgré tout un chiffre inexpliqué de google / cpc vs direct, cela peut être dû à des problématiques côté Google qui sont en cours de correction. Une déjà évoquée dans la communauté concerne notamment l’impact du user-id dans de rares cas d’attribution.
En synthèse
Je ne connais aucun analyste qui aime perdre du temps sur des sujets d’écarts. Pour approcher cette problématique avec efficacité, je vous ai proposé ici une méthode pour émettre et éliminer des hypothèses rapidement.
Très souvent, j’ai pu constater qu’une mauvaise formulation des problèmes à la source engendre un manque d’efficacité sur ces questions, c’est pour cela qu’il est important de former vos équipes à GA4 comme nouvel outil et à ses définitions associées.
Que se passe-t-il si, après une analyse rigoureuse, des problèmes d’écarts persistent ?
J’en appelle aussi au bon sens du webanalyste à définir avec certitude ce qu’est un écart acceptable, ce qu’est une anomalie, et à prendre les chiffres que nous fournit un nouvel outil comme tels, si tant est que le pilotage du business n’est pas remis en cause.
Inscrivez-vous à notre newsletter dédiée aux métiers de l’Analytics, du tracking et du CRO :