
Le traitement des données grâce à l’IA ou lorsque les signaux faibles deviennent un argument fort

Contexte :
Dans une lettre fictive à sa grand-mère, Natacha Dagneaud, fondatrice de l’institut d’Etudes Qualitatives Séissmo, explique les avantages de l’intelligence artificielle dans l’analyse de textes et son utilisation au travers d’exemples concrets.
Bonjour Mamie,
Tu dis toujours que j’exerce un drôle de métier. Oui, j’observe des personnes pendant des heures, je leur pose des questions (presque comme une journaliste !), puis j’interprète leurs réponses – tout en prêtant une attention particulière à leurs silences, leurs éclats de rire… Parce que souvent les gens ne disent pas toute la vérité. Et ça, c’est toi qui me l’as appris !
Tu te doutes bien que durant ces longues interviews, beaucoup de choses différentes sont dites. Par exemple, nous venons d’accompagner 27 femmes ménopausées dans leur vie quotidienne pendant sept jours (via un blog, une sorte de journal intime mais sur internet). Résultat : 189 pages de réponses à lire, soit précisément 92 669 mots à analyser. Certes, compter les mots n’est pas sorcier, le logiciel Word le fait très bien – mais attention, ce n’est pas de l’Intelligence Artificielle.
C’est vrai, tu m’as appris à lire très tôt (Te rappelles-tu du roman de Boris Vian « J’irai cracher sur vos tombes » juste avant mes 15 ans ?). Mais lire et interpréter, ce n’est pas la même chose … Figure-toi qu’il existe aujourd’hui des technologies nous permettant de réinterpréter notre travail.
Un autre exemple : nous avons récemment interrogé 40 personnes faisant leurs courses dans des supermarchés différents. Ces entretiens ont été menés selon la méthode de « l’entretien cognitif », que nous avons ironiquement volée à la police.
Le principe : durant plus d’une heure, les interrogés racontent ce qu’ils ont vécu dans une situation récente précise (ils sont immergés dans leurs souvenirs comme s’ils revivaient la scène). C’est un moyen scientifique d’augmenter la capacité de la mémoire pour obtenir des témoignages plus précis.
Je le ferai avec toi lorsque tu chercheras à nouveau tes clés 😊.
Quoi qu’il en soit, nous avons récolté en moyenne 4 500 mots par interview, soit 180 000 mots pour les 40 personnes interrogées (sans caractères superflus !).
Comment mon cerveau pourrait-il traiter une telle quantité ? Evidemment je vais beaucoup filtrer, et plutôt mettre en avant les aspects avec lesquels j’ai le plus d’affinité. Je sais que je dois être très vigilante et mes collègues aussi. Eh oui, nous ne sommes pas des robots.
C’est pourquoi, il y a un an, nous avons pris contact avec de nombreux fournisseurs capables de nous aider à traiter intelligemment cette masse de données. Nous avons mis du temps à trouver un partenaire de qualité, et avons finalement trouvé l’entreprise « Synomia » avec qui nous collaborons sur de nombreux projets. Synomia est une entreprise spécialisée dans l’intelligence artificielle appliqué à l’analyse de textes, en grande quantité. Grosso modo ils identifient et trient les mots dans les textes pour nous aider à découvrir les idées qui y sont contenues. Ils possèdent leur propre technologie et des équipes qui nous accompagnent pour en tirer le meilleur.
Ils sont basés à Paris mais peuvent gérer de nombreuses langues dans leur logiciel (nous utilisons actuellement l’anglais, l’allemand et le français).
Jusqu’à présent, ils travaillaient avec nos collègues du quantitatif, qui traitent des phrases moins compliquées, mais en plus grand nombre.
Désormais ils travaillent aussi avec nous, chercheurs du qualitatif, où c’est l’inverse : nous interviewons peu de personnes mais produisons des textes plus complexes.
Nous collaborons en étroite collaboration avec leur équipe R&D pour clarifier nos besoins et nos exigences.
Par exemple, le contexte à partir duquel chaque mot a été créé est très important pour nous. Ils ont donc développé une fonctionnalité supplémentaire, qui nous permet de recontextualiser un verbatim (c’est-à-dire la VO du consommateur).
Nous avons accès à une plateforme dédiée où nos textes – nos sujets d’interviews – sont « stockés » jusqu’à ce que nous les « thématisions », les assignant ainsi à un sujet significatif.
Nous pouvons trier, rechercher, grouper, catégoriser des sujets et des sensations. C’est la maîtrise du chaos ! Mais est-il si important de compter les mots ou quantifier les occurrences ? Après tout, tout le monde ne parle pas de la même façon. Et avec ce système, le bavard risque de se faire entendre davantage, non ?
Sauf que lorsqu’un sujet ne nous intéresse pas, nous avons tendance à ne pas en discuter ! De la même manière que nous allons nous échauffer et beaucoup parler sur un sujet qui nous touche.
Donc au final, peu importe ce que les gens pensent d’un sujet. L’important est d’identifier si le sujet « fait couler de l’encre ». Et dès qu’ils en parlent, nous pouvons en tirer du sens ! C’est pourquoi nous devons prendre en compte la « masse », et c’est nouveau pour des chercheurs qualitatifs.
Je voudrais te faire comprendre tout ce que ce logiciel a changé dans mon quotidien (c’est un logiciel SaaS, c’est comme ton abonnement à Reader’s Digest, mais en virtuel). C’est un peu comme une machine à laver. Tu dois trier soigneusement ton linge et régler sur la bonne température. La machine ne te remplace pas, et ne peut pas deviner tes intentions, mais fait le travail pénible de manière rapide et précise, si tu la contrôles correctement. En revanche si tu mélanges n’importe quelle matière brute dedans, tu obtiendras un gloubi-boulga à la sortie.
C’est la même chose avec l’intelligence artificielle et les logiciels de syntaxe (cela signifie simplement que l’ordinateur comprend la structure grammaticale des phrases) : analyse claire des verbes, adjectifs, subordonnés, pronoms, syntagmes … Cela me fait sourire car les leçons de latin n’ont pas été vaines. L’IA nous confronte à de vrais enjeux :
- Sur quels principes trions-nous ce « linge », c’est-à-dire les textes ? Pouvons-nous inclure TOUTES les phrases des consommateurs et des animateurs sans qu’elles ne biaisent trop le sens de l’ensemble ? La machine révèle que certains enquêteurs parlent beaucoup, parfois trop.
- Comment retranscrit-on des enregistrements audio sous format électronique ? Cela prend du temps, coûte de l’argent et nécessite une excellente formation des transcripteurs.
- Autre problème…. Quelles règles de ponctuation établir pour retranscrire une conversation orale ? La machine considère les phrases comme une unité et les « découpe » le long de la ponctuation. Lorsqu’une personne décrit une expérience avec des hésitations, des onomatopées ou des tics de langage (« et … mmmh ensuite … enfin … »), est-ce que cela constitue une seule et même phrase ? Ou bien nos transcripteurs doivent-ils mettre des points ou points-virgules et de fait créer différentes phrases ? Le nombre total de verbatim reste nécessaire, pour pouvoir pondérer les sujets. Et ce détail est loin d’être insignifiant.
- Comment faire comprendre à nos clients que l’intérêt réside aussi dans le poids des mots, et pas uniquement dans le nombre des personnes qui en parlent ? J’ai d’ailleurs écrit un article à ce sujet si tu veux !
POUR VOIR L’ARTICLE SUR LE POID DES MOTS C’EST AUSSI ICI
Grâce à ce traitement digne d’une usine, les mots sont reconnus, classés et comptés. Jusqu’ici, nous le faisions à la « Mano » 😉 : nous identifiions des unités de lecture significatives, les écrivions, puis les rédigions dans des rapports comprenant généralement de longues phrases. Jusqu’ici, compter des mots ou des phrases, personne n’y aurait pensé. A la main c’est tout simplement impossible. D’ailleurs, notre travail n’en est pas fondamentalement modifié : c’est toujours notre capacité d’analyse et d’interprétation qui fait la différence. Mais la machine de Synomia ouvre de nouvelles possibilités pour traiter notre matière première, et permet aux chercheurs qualitatifs d’approfondir leurs recherches. Par exemple, j’aime me concentrer sur les verbes lors de l’analyse, car ils trahissent une intention.
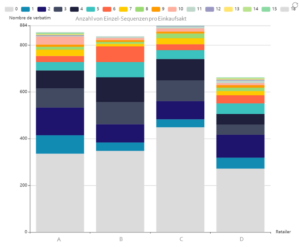
La somme des mots rend visible des phénomènes difficilement quantifiables à l’oeil nu, comme le montre le graphique ci-dessous. Les clients qui ont fait leurs courses dans le magasin D ont visité moins de rayons et ont consommé pour un panier moyen plus petit.
Cette enseigne a donc du mal à séduire ses clients tout au long de leur parcours en magasin.
Figure 1 : Nombre de séquences simples par acte d’achat
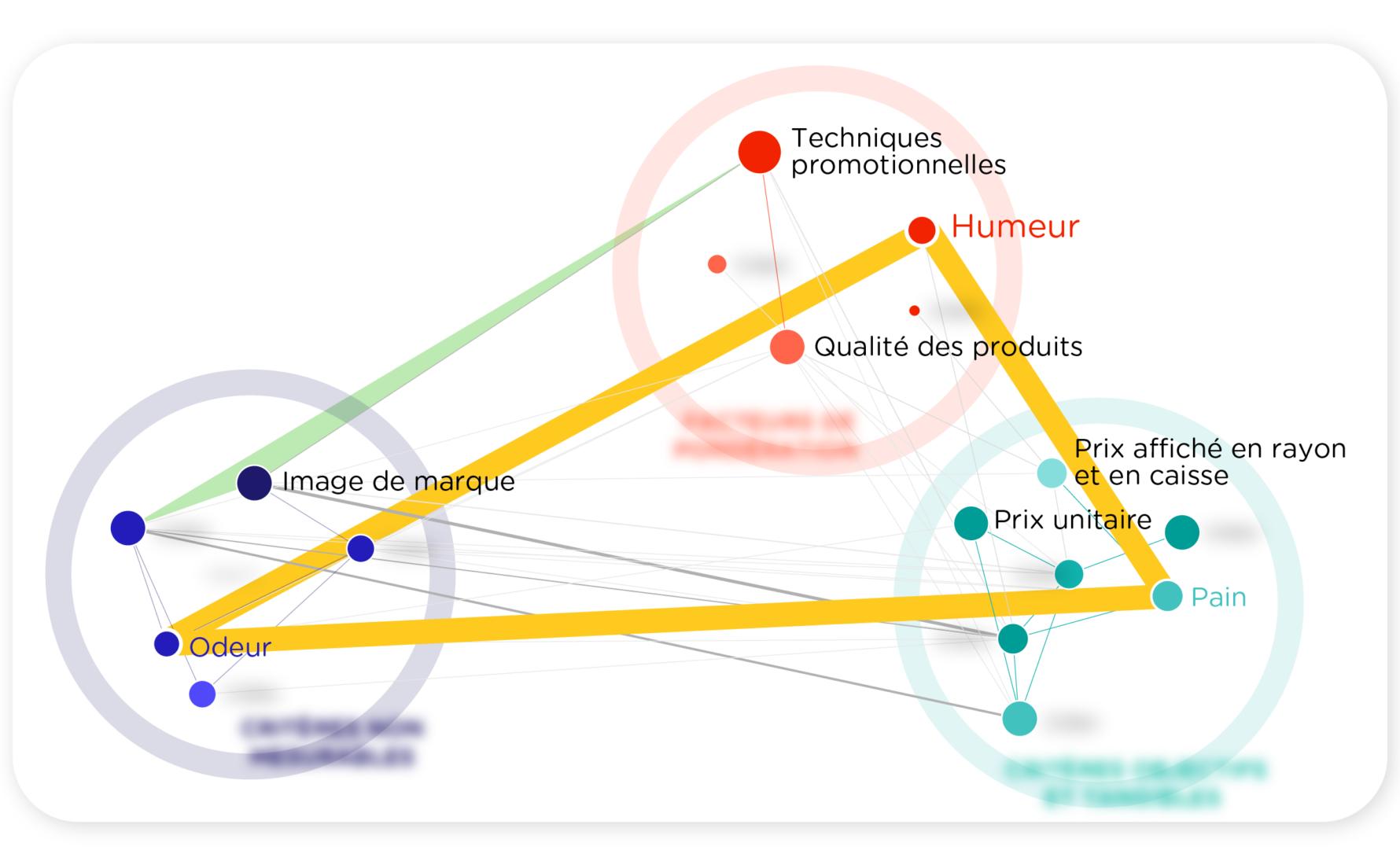
Enfin, il faut que je te raconte quelques détails amusants que j’ai découverts grâce à l’IA, et que je n’avais jamais perçus jusque-là.
- D’abord sur l’importance du pain : il s’agissait du dix-huitième mot le plus utilisé dans notre récente étude sur l’achat de produits alimentaires. J’étais bien sûr consciente que dans un pays francophone, lorsque l’on fait ses courses, on achète quasi-systématiquement du pain. Mais que les gens évoquent à ce point le pain comme un élément important de leur expérience en magasin, je ne l’aurais pas imaginé. C’est quand j’ai croisé cette information avec les impressions sensorielles que les consommateurs ressentent dans un magasin que j’ai eu la révélation. Sans odeur de pain, pas de joie dans le magasin !
- Une autre fois, j’ai été surprise de découvrir la valeur de la négation. J’ai tendance à accorder plus d’attention aux affirmations positives : ce qu’un être humain fait, choisit, prend en main … Mais le logiciel est tellement intelligent qu’il détecte également quand les personnes « ne font pas ». Pour cela, il identifie le nombre de négations dans une phrase. J’ai donc été en mesure de savoir dans quels magasins les acheteurs avaient un comportement d’évitement. Dans les supermarchés les plus coûteux, les consommateurs avaient en quelque sorte intériorisé une sorte d’autofreinage, une inhibition ; ils mettaient donc plus en avant dans le récit de leur expérience qu’ils n’avaient « pas acheté / pas choisi » tel ou tel produit.
- Dernière anecdote : lors d’une étude sur le shampoing antipelliculaire, lequel existait en formule de couleur orange chatoyante ou blanche de consistance crémeuse. Le fabricant voulait savoir si la couleur orange posait problème. Au lieu de demander directement aux gens en les forçant à donner une réponse, ce qui aurait biaisé leur discours, nous les avons laissé partager leurs expériences en matière de shampoing. Nous avons immédiatement remarqué en quoi le schéma de couleurs était un pilier de l’identité du produit, avec notamment de fortes associations.
Voilà, Mamie, il reste encore beaucoup à dire et je te promets de te tenir au courant – mais dans cette lettre aussi , les mots nous sont comptés.