
Google Analytics 4 – Assurer la continuité du pilotage dans BigQuery


Simon Gay, Consultant Senior data analyst chez Converteo, expert des sujets d’analytics engeneering : GCP, BigQuery. Il accompagne nos clients sur l’utilisation et l’appropriation de leurs données marketing pour leurs analyses.
Régulièrement, des clients viennent nous voir avec cette problématique : comment assurer la transition entre mes datasets BigQuery UA et GA4 ?
Il est en effet crucial pour les équipes de pouvoir piloter leurs KPIs sans discontinuité.
Universal Analytics, dans sa version 360, baissera définitivement le rideau en juillet. On constate cependant que de nombreux clients désirent l’utiliser jusqu’à la fin, et que la résistance au changement et à la transition vers GA4 est forte.
Nous évoquons ici plusieurs approches pour lever les freins concernant l’adoption de l’outil :
- Connaître les différents écueils du data model GA4 dans BigQuery
- Re-modéliser convenablement ses données pour matcher avec Universal Analytics
Connaître le data model GA4 dans BigQuery
L’export des données GA4 dans BigQuery permet d’avoir accès à des données brutes et granulaires ce qui offre des opportunités de pilotage et d’analyse pour les équipes Data Marketing.
Deux modèles de données différents
Au contraire d’Universal Analytics qui propose un modèle de données exportées parfois complexe basé sur une imbrication de hits et de sessions, GA4 opte pour un modèle de données plus “à plat” où chaque ligne est un évènement. On a donc deux outils différents et deux modèles différents.
Pour chaque KPI que l’on va vouloir piloter en continu, il faut au préalable se poser la question de son calcul entre les différents modèles, pour savoir si, intellectuellement, il est possible de les comparer.
A ce sujet, nous vous conseillons la lecture de https://www.ga4bigquery.com/ qui propose des tas de requêtes SQL préconstruites sur les indicateurs de base.
… et des écueils à connaître dans le data model GA4
Le modèle d’export des données GA4 propose quelques certains défis qu’il est important de surmonter. Voici les principaux que nous rencontrons dans nos missions :
- La gestion des types : GA4 classe automatiquement un paramètre dans une colonne selon son type (integer / string / double value / float). Renvoyer la bonne valeur d’un paramètre est un petit casse tête en SQL qu’il faut savoir maîtriser : les fonctions COALESCE() et SAFE_CAST() sont vos meilleures alliées. Les principales fonctions à connaître sont listées dans cet article Medium ; ainsi que sur celui-ci spécifiquement pour la gestion des dates
Un trait d’humeur sur X

- La modification des données : les données peuvent être modifiées – dans la table journalière – jusqu’à 72h après disponibilité. En conséquence, vos routines de calcul et d’appels à ces tables doivent référencer les tables d’origine pendant 3 jours si vous voulez avoir un calcul exhaustif.
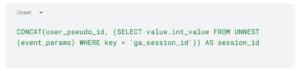
- Unicité du session_id : rappeler qu’un ID de session se requête en combinant le ga_session_id et le user_pseudo_id
- Gestion du consent_mode : les hits non-consentis “privacy_info.analytics_storage = no” sont inclus dans l’export – même si avec un nombre de paramètres associés minimes – pensez à ne pas les compter
- Absence de dimension à la session – vu que le modèle est à l’event – au contraire d’Universal Analytics. Vous devrez donc “sessioniser” certaines dimensions.
- Pas d’intégration avec les outils Ads – la réconciliation doit se faire soi-même
- Pas de données d’attribution – qui est également à recalculer par soi-même – notamment si vous voulez reproduire une logique “last-click non direct”
- Des événements envoyés en batch ont le même event timestamp – c’est à vous au niveau de la collecte de créer un timestamp distinct si vous souhaitez recréer une notion d’ordre – en attendant une évolution côté Google !
Une fois que nous avons défini clairement les KPIs que nous souhaitons suivre et leur méthode de calcul, nous pouvons aborder la question de leur rapprochement entre UA et GA4.
Modéliser et rapprocher les données entre GA4 et UA
Pour travailler sur les données GA4, nous recommandons de les subdiviser en sous-ensembles de tables répondant à une logique de scope : users, sessions, ecommerce, événements, pages…
Le principal intérêt de cette subdivision étant de maximiser la performance et de diminuer les coûts – autrement dit éviter d’appeler la table principale qui peut contenir des dizaines de millions de lignes à chaque requête.
Prenons un exemple : notre équipe Data Marketing pilote le KPI “Fréquence de sessions par utilisateur” dans Universal Analytics. Nous créons une table “ga4_user” qui calcule ce KPI pour GA4 ; puis nous mergeons ensuite ce KPI avec son historique Universal Analytics.
Chez Converteo, nous avons décidé de nous appuyer sur les outils de modelling standards du marché pour effectuer cette partie : DBT et Dataform.
Deux exemples publics existent pour montrer les capacités de ces outils :
- Pour DBT, la ressource la plus intéressante concerne le package Velir/dbt-ga4 qui permet de recréer des tables au niveau user / session / page et d’y associer des taux de conversion par exemple.
- Pour Dataform, j’apprécie le travail fourni par Artem Korneev notamment pour la gestion du modèle d’attribution
Notre rôle chez Converteo est de créer et de livrer toutes les tables pré-calculées clé-en-main pour les équipes de nos clients et leur offrir une continuité de pilotage.
Les limites de l’approche
Prenons un exemple de table “session” avec différents KPI associés :
- Taux d’accès au checkout
- Nb de sessions par source / medium
Une fois les données modélisées et réconciliées, nous pouvons les visualiser dans l’outil de notre choix (Looker Studio / Tableau). Cependant, les courbes ne se suivront pas exactement: car les sessions ne sont pas calculées de la même manière entre les outils.
Même s’il peut être tentant de vouloir “redresser” ses courbes avec modèle de Data Science, l’approche est de notre expérience – assez vaine.
C’est pour cela qu’il est essentiel, dès la phase de cadrage, de bien choisir les KPIs et de challenger via un Sanity Check le niveau de confiance à rapprocher GA4 et UA.
L’incontournable BigQuery
L’utilisation de BigQuery pour GA4 offre un vaste champ des possibles en termes d’analyse marketing : analyse de data quality, clustering, recréation de visualisations personnalisée.
C’est également une belle opportunité offertes aux organisations pour progresser dans leur usage d’outils de modelling comme DBT et Dataform. L’utilisation de BigQuery, intégré au stack GCP, avec toutes les innovations autour de Gemini notamment, est clairement un marqueur de maturité digitale et ce vers quoi notre métier se dirige.
L’avantage est qu’il n’est jamais trop tard pour se lancer ou s’y perfectionner, bien qu’il faille connaître les conditions : la réussite d’un projet GA4 x BigQuery nécessite à la fois de l’expérience – car les problèmes inhérents au modèle de données sont nombreux – et un engagement important des équipes pour maintenir la qualité des données au cours du temps.
Inscrivez-vous à notre newsletter dédiée aux métiers de l’Analytics, du tracking et du CRO :










