
To build my editorial strategy, I want to understand how the media addresses my topics

Unstructured data currently represents between 80% and 90% of the total data produced globally and includes content, conversations, and statements both online and offline.
To build my editorial strategy, I want to understand how the media addresses my topics
Did you know? The media approaches the topic of beer from four angles: health, alcohol content, pure controversy, and the festive side.
In fact, here we’re not really talking about beer (oops) but rather about how intelligent processing of unstructured data quickly gave us this result. The challenge is twofold: from a very large amount of semantic data, we aim to understand a topic, particularly how mainstream and specialized media approach it. The goal is to extract relevant content ideas or editorial angles and adopt the best way to discuss it or address a specific target.
Whether in agencies, for a client, or for brand communication.
Unstructured data currently represents between 80% and 90% of the total data produced in the world, encompassing content, conversations, and statements both online and offline. These data have already proven their value, but the complexity of their processing makes this valuation lengthy and sometimes impossible. While collection is relatively straightforward, once these data are collected, determining their use often leads to the critical question, “So what?”
To give you an example with the theme of beer, we undertook a mission for one of our clients who needed to address this issue. Objective: to understand the media tone on a specific topic.
Following a brief, the issue is as follows: “Beer as a pillar of friendship.” From experience, our client knew that the topic was sensitive. To avoid a “bad buzz,” it is crucial to research beforehand and not to tackle just any subject. One solution is to gauge the “pulse” of the media to understand the tone used on this potentially controversial topic, in order to confirm or refute their intuition.

Why the media? Because they represent a significant source of information, especially on controversial topics, containing studies, expert or consumer testimonials, detailed investigations, or sensational articles.
But the most interesting aspect is to identify those that have performed best, generated the most buzz, been the best referenced—essentially, those that have most engaged consumers. This helps understand how they discuss the topic, what interests them, and avoid creating content that might be considered “off-topic,” with the aim of driving traffic.
This can be considered an initial “filtering” step. There’s no need to attempt to aggregate all available semantic data; prioritize what is most relevant. Here, it seems more pertinent to rely on mainstream media as well as specialized blogs to get a comprehensive view of the discussion and avoid pursuing a poorly aligned topic with the market.
We mentioned data earlier, so how does it work?
To identify mainstream media or blogs, you can indeed use your search engine to enter a query such as “drinking beer” and list the first URLs you find. Then, categorize them, identify whether the articles have a positive or negative tone, and ideally check if a competitor is already covering the topic.
But for it to be effective, you need a sample that is representative and relevant to your issue. However, when you enter this query, you might also come across “off-topic” results, such as the names of major bars in the city that are not of interest to you.
Moreover, if you want to perform this exercise qualitatively, it requires time.
However, what if we told you that tools already exist to handle this entire process of data collection, minimize irrelevant “noise” not related to your goal, provide a direct view of the different concepts associated with your query, showcase the best media articles related to each concept with their competition score? All this, with the ability to check if your brand or client is already positioned on the topic? In just 10 minutes!
We present to you our application, “Discovery.”
Another shaky technology you can find anywhere?
Not at all; it is a very user-friendly application based on robust AI technology. When you enter a query, for example, “drinking beer,” the application will “crawl the web” or analyze it to extract the top 100 articles from blogs or major media outlets.
But beware, the machine learning technology used intelligently links the initial query to the various topics found through the search engine. The results will not appear as simple Google search results, but will be ordered by relevance to the objective, thus avoiding the “noise” we mentioned earlier.
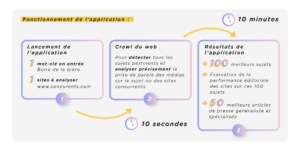
A concrete example of analysis
Our client starts the application by entering “drinking beer.”
In 10 minutes, they retrieve, for each of the 100 topics related to the theme, the top articles from general media and the top articles from specialized media.
Why 100? There is no need to go further; 100 articles already represent a good sample that will provide the necessary information for your research. We do not intend to overwhelm you with information.
What does “best” mean concretely? Simply those that are the most successful on the web and also the most relevant to your initial query.
He now has a complete press review at his disposal and quickly began classifying the articles based on the angle they take on the subject.
He soon realized several key points: firstly, almost all the articles have a controversial tone. Secondly, after about twenty minutes of analyzing the article titles, four main themes emerged: health, alcohol consumption, pure controversy, and the festive aspect.
Only 20% of the articles focus on the festive side, while more than 60% discuss the risks and dangers of alcohol to health.
Here is an example of the results:
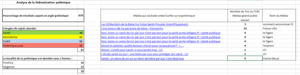
The final situation is quite simple. Starting from the desired topic, “beer as a pillar of friendships,” it became clear that addressing the subject solely from a festive angle while ignoring the aspect of prevention would be a mistake, likely leading to negative repercussions in the media and, of course, on social media.
However, thanks to the findings, he was able not only to recommend combining both aspects but also to support his argument with concrete examples.